Вступление.
Если вы собираетесь создавать собственные базы данных, то неплохо было бы придерживаться правил проектирования баз данных, так как это обеспечит долговременную целостность и простоту обслуживания ваших данных. Данное руководство расскажет вам что представляют из себя базы данных и как спроектировать базу данных, которая подчиняется правилам проектирования реляционных баз данных.
Базы данных – это программы, которые позволяют сохранять и получать большие объемы связанной информации. Базы данных состоят из таблиц, которые содержат информацию. Когда вы создаете базу данных необходимо подумать о том, какие таблицы вам нужно создать и какие связи существуют между информацией в таблицах. Иначе говоря, вам нужно подумать о проекте вашей базы данных. Хороший проект базы данных, как было сказано ранее, обеспечит целостность данных и простоту их обслуживания.
Структурированный язык запросов (SQL).
База данных создается для хранения в ней информации и получения этой информации при необходимости. Это значит, что мы должны иметь возможность помещать, вставлять (INSERT) информацию в базу данных и мы хотим иметь возможность делать выборку информации из базы данных (SELECT).
Язык запросов к базам данных был придуман для этих целей и был назван "Структурированный язык запросов" или SQL. Операции вставки данных (INSERT) и их выборки (SELECT) – части этого самого языка.
Реляционная модель.
В этом руководстве я покажу вам как создавать реляционную модель данных. Реляционная модель – это модель, которая описывает как организовать данные в таблицах и как определить связи между этими таблицами.
Правила реляционной модели диктуют, как информация должна быть организована в таблицах и как таблицы связаны друг с другом. В конечном счете результат можно предоставить в виде диаграммы базы данных или, если точнее, диаграммы "сущность-связь".
РСУБД.
РСУБД, которую я использовал для создания таблиц примеров – MySQL. MySQL – наиболее популярная РСУБД и она бесплатна.
История.
В 70-х – 80-х годах, когда компьютерные ученые все еще носили коричневые смокинги и очки с большими, квадратными оправами, данные хранились бесструктурно в файлах, которые представляли собой текстовый документ с данными, разделенными (обычно) запятыми или табуляциями.

Так выглядели профессионалы в сфере информационных технологий в 70-е. (Слева внизу находится Билл Гейтс).
Текстовые файлы и сегодня все еще используются для хранения малых объемов простой информации. Comma-Separated Values (CSV) — значения, разделённые запятыми, очень популярны и широко поддерживаются сегодня различным программным обеспечением и операционными системами. Microsoft Excel – один из примеров программ, которые могут работать с CSV–файлами. Данные, сохраненные в таком файле могут быть считаны компьютерной программой.
Программа, производящая чтение данного файла, должна быть уведомлена о том, что данные разделены запятыми. Если программа хочет выбрать и вывести категорию, в которой находится урок 'Database Design Tutorial', то она должна строчка за строчкой производить чтение до тех пор, пока не будут найдены слова 'Database Design Tutorial' и затем ей нужно будет прочитать следующее за запятой слово для того, чтобы вывести категорию Software.
Таблицы баз данных.
Чтение файла строчка за строчкой не является очень эффективным. В реляционной базе данных данные хранятся в таблицах. Таблица ниже содержит те же самые данные, что и файл. Каждая строка или “запись” содержит один урок. Каждый столбец содержит какое-то свойство урока. В данном случае это заголовок (title) и его категория (category).
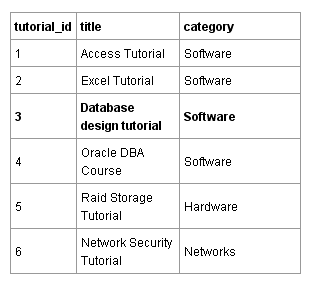
Компьютерная программа могла бы осуществить поиск в столбце tutorial_id данной таблицы по специфическому идентификатору tutorial_id для того, чтобы быстро найти соответствующие ему заголовок и категорию. Это намного быстрее, чем поиск по файлу строка за строкой, подобно тому, как это делает программа в текстовом файле.
Современные реляционные базы данных созданы так, чтобы позволять делать выборку данных из специфических строк, столбцов и множественных таблиц, за раз, очень быстро.
История реляционной модели.
Реляционная модель баз данных была изобретена в 70-х Эдгаром Коддом (Ted Codd), британским ученым. Он хотел преодолеть недостатки сетевой модели баз данных и иерархической модели. И он очень в этом преуспел. Реляционная модель баз данных сегодня всеобще принята и считается мощной моделью для эффективной организации данных.
Сегодня доступен широкий выбор систем управления базами данных: от небольших десктопных приложений до многофункциональных серверных систем с высокооптимизированными методами поиска. Вот некоторые из наиболее известных систем управления реляционными базами данных (РСУБД):
- Oracle – используется преимущественно для профессиональных, больших приложений.
- Microsoft SQL server – РСУБД компании Microsoft. Доступна только для операционной системы Windows.
- MySQL – очень популярная РСУБД с открытым исходным кодом. Широко используется как профессионалами, так и новичками. Что еще нужно?! Она бесплатна.
- IBM – имеет ряд РСУБД, наиболее известна DB2.
- Microsoft Access – РСУБД, которая используется в офисе и дома. На самом деле – это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
Характеристики реляционных баз данных.
Реляционные базы данных разработаны для быстрого сохранения и получения больших объемов информации. Ниже приведены некоторые характеристики реляционных баз данных и реляционной модели данных.
Использование ключей.
Каждая строка данных в таблице идентифицируется уникальным “ключом”, который называется первичным ключом. Зачастую, первичный ключ это автоматически увеличиваемое (автоинкрементное) число (1,2,3,4 и т.д). Данные в различных таблицах могут быть связаны вместе при использовании ключей. Значения первичного ключа одной таблицы могут быть добавлены в строки (записи) другой таблицы, тем самым, связывая эти записи вместе.
Отсутствие избыточности данных.
В проекте базы данных, которая создана с учетом правил реляционной модели данных, каждый кусочек информации, например, имя пользователя, хранится только в одном месте. Это позволяет устранить необходимость работы с данными в нескольких местах. Дублирование данных называется избыточностью данных и этого следует избегать в хорошем проекте базы данных.
Ограничение ввода.
Используя реляционную базу данных вы можете определить какой вид данных позволено сохранять в столбце. Вы можете создать поле, которое содержит целые числа, десятичные числа, небольшие фрагменты текста, большие фрагменты текста, даты и т.д.
Когда вы создаете таблицу базы данных вы предоставляете тип данных для каждого столбца. К примеру, varchar – это тип данных для небольших фрагментов текста с максимальным количеством знаков, равным 255, а int – это числа.
Помимо типов данных РСУБД позволяет вам еще больше ограничить возможные для ввода данные. Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (логины), или адреса электронной почты.
Эти ограничения дают вам контроль над целостностью ваших данных и предотвращают ситуации, подобные следующим:
- ввод адреса (текста) в поле, в котором вы ожидаете увидеть число
- ввод индекса региона с длиной этого самого индекса в сотню символов
- создание пользователей с одним и тем же именем
- создание пользователей с одним и тем же адресом электронной почты
- ввод веса (числа) в поле дня рождения (дата)
Поддержание целостности данных.
Настраивая свойства полей, связывая таблицы между собой и настраивая ограничения, вы можете увеличить надежность ваших данных.
Назначение прав.
Большинство РСУБД предлагают настройку прав доступа, которая позволяет назначать определенные права определенным пользователям. Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT (выборка), INSERT (вставка), DELETE (удаление), ALTER (изменение), CREATE (создание) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов (SQL).
Структурированный язык запросов (SQL).
Для того, чтобы выполнять определенные операции над базой данных, такие, как сохранение данных, их выборка, изменение, используется структурированный язык запросов (SQL). SQL относительно легок для понимания и позволяет в т.ч. и уложненные выборки, например, выборка связанных данных из нескольких таблиц с помощью оператора SQL JOIN.
То, как вы спроектируете базу данных будет оказывать непосредственное влияние на запросы, которые вам будет необходимо выполнить, чтобы получить данные из базы данных. Это еще одна причина, почему вам необходимо задуматься о том, какой должна быть ваша база. С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.
Переносимость.
Реляционная модель данных стандартна. Следуя правилам реляционной модели данных вы можете быть уверены, что ваши данные могут быть перенесены в другую РСУБД относительно просто.
Таблицы и первичные ключи.
Как вы уже знаете из прошлых частей, данные хранятся в таблицах, которые содержат строки или по-другому записи. Ранее я приводил пример таблицы, содержащей информацию об уроках. Давайте снова на нее взглянем.
В таблице имеются 6 уроков. Все 6 – разные, но для каждого урока значения одинаковых полей хранятся в таблице, а именно: tutorial_id (идентификатор урока), title (заголовок) и category (категория).
Tutorial_id – первичный ключ таблицы уроков. Первичный ключ – это значение, которое уникально для каждой записи в таблице.
Первичные ключи в повседневной жизни.
В базе данных первичные ключи используются для идентификации. В жизни первичные ключи вокруг нас везде. Каждый раз, когда вы сталкиваетесь с уникальным числом это число может служить первичным ключом в базе данных (может, но не обязательно должно использоваться как таковое. Все базы данных способны автоматически генерировать уникальное значение для каждой записи в виде числа, которое автоматически увеличивается и вставляется вместе с каждой новой записью).
Несколько примеров:
- Номер заказа, который вы получаете при покупке в интернет-магазине может быть первичным ключом какой-нибудь таблицы заказов в базе данных этого магазина, т.к. он является уникальным значением.
- Номер социального страхования может быть первичным ключом в какой-нибудь таблице в базе данных государственного учреждения, т.к. она также как и в предыдущем примере уникален.
- Номер счета-фактуры может быть использован в качестве первичного ключа в таблице базы данных, в которой хранятся выданные клиентам счета-фактуры.
- Числовой номер клиента часто используется как первичный ключ в таблице клиентов.
Что объединяет эти примеры? То, что во всех из них в качестве первичного ключа выбирается уникальное, не повторяющееся значение для каждой записи. Еще раз. Значения поля таблицы базы данных, выбранного в качестве первичного ключа, всегда уникально.
Что характеризует первичный ключ? Характеристики первичного ключа.
- Первичный ключ служит для идентификации записей.
Первичный ключ используется для идентификации записей в таблице, для того, чтобы каждая запись стала уникальной. Еще одна аналогия... Когда вы звоните в службу технической поддержки, оператор обычно просит вас назвать какой-либо номер (договора, телефона и пр.), по которому вас можно идентифицировать в системе.
Если вы забыли свой номер, то оператор службы технической поддержки попросит предоставить вас какую-либо другую информацию, которая поможет уникальным образом идентифицировать вас. Например, комбинация вашего дня рождения и фамилия. Они тоже могут являться первичным ключом, точнее их комбинация.
- Первичный ключ уникален.
Первичный ключ всегда имеет уникальное значение. Представьте, что его значение не уникально. Тогда его бы нельзя было использовать для того, чтобы идентифицировать данные в таблице. Это значит, что какое-либо значение первичного ключа может встретиться в столбце, который выбран в качестве первичного ключа, только один раз. РСУБД устроены так, что не позволят вам вставить дубликаты в поле первичного ключа, получите ошибку.
Еще один пример. Представьте, что у вас есть таблица с полями first_name и last_name и есть две записи:
| first_name | last_name | | vasya |pupkin | | vasya |pupkin |
Т.е. есть два Васи. Вы хотите выбрать из таблицы какого-то конкретного Васю. Как это сделать? Записи ничем друг от друга не отличаются. Вот здесь и помогает первичный ключ. Добавляем столбец id (классический вариант синтетического первичного ключа) и...
id | first_name | last_name | 1 | vasya |pupkin | 2 | vasya |pupkin |
Теперь каждый Вася уникален.
- Типы первичных ключей.
Обычно первичный ключ – числовое значение. Но он также может быть и любым другим типом данных. Не является обычной практикой использование строки в качестве первичного ключа (строка – фрагмент текста), но теоретически и практически это возможно.
Часто первичный ключ состоит из одного поля, но он может быть и комбинацией нескольких столбцов, например, двух (трех, четырех...). Но вы помните, что первичный ключ всегда уникален, а значит нужно, чтобы комбинация n-го количества полей, в данном случае 2-х, была уникальна.
- Автонумерация.
Поле первичного ключа часто, но не всегда, обрабатывается самой базой данных. Вы можете, условно говоря, сказать базе данных, чтобы она сама автоматически присваивала уникальное числовое значение каждой записи при ее создании. База данных, обычно, начинает нумерацию с 1 и увеличивает это число для каждой записи на одну единицу. Такой первичный ключ называется автоинкрементным или автонумерованным. Использование автоинкрементных ключей – хороший способ для задания уникальных первичных ключей. Классическое название такого ключа – суррогатный первичный ключ. Такой ключ не содержит полезной информации, относящейся к сущности (объекту), информация о которой хранится в таблице, поэтому он и называется суррогатным.
Связывание таблиц с помощью внешних ключей.
Когда я начинал разрабатывать базы данных я часто пытался сохранять информацию, которая казалась родственной, в одной таблице. Я мог, например, хранить информацию о заказах в таблице клиентов. Ведь заказы принадлежат клиентам, верно? Нет. Клиенты и заказы представляют собой отдельные сущности в базе данных. И тому и другому нужна своя собственная таблица. А записи в этих двух таблицах могут быть связаны для того, чтобы установить отношения между ними. Проектирование базы данных – это решение двух вопросов:
- определение того, какие сущности вы хотите хранить в ней
- какие связи между этими сущностями существуют
Один-ко-многим.
Клиенты и заказы имеют связь (состоят в отношениях) один-ко-многим потому, что один клиент может иметь много заказов, но каждый конкретный заказ (их множество) оформлен только одним клиентом, т.е. может иметь только одного клиента.
Какую информацию мы будем хранить? Решаем первый вопрос.
Для начала мы определимся какую информацию о заказах и о клиентах мы будем хранить. Чтобы это сделать мы должны задать себе вопрос: “Какие единичные блоки информации относятся к клиентам, а какие единичные блоки информации относятся к заказам?”
Проектируем таблицу клиентов.
Заказы действительно принадлежат клиентам, но заказ – это это не минимальный блок информации, который относится к клиентам (т.е. этот блок можно разбить на более мелкие: дата заказа, адрес доставки заказа и пр., к примеру).
Поля ниже – это минимальные блоки информации, которые относятся к клиентам:
- customer_id (primary key) – идентификатор клиента
- first_name — имя
- last_name — отчество
- address — адрес
- zip_code – почтовый индекс
- country — страна
- birth_date – дата рождения
- username – регистрационное имя пользователя (логин)
- password – пароль
Давайте перейдем к непосредственному созданию этой таблицы.
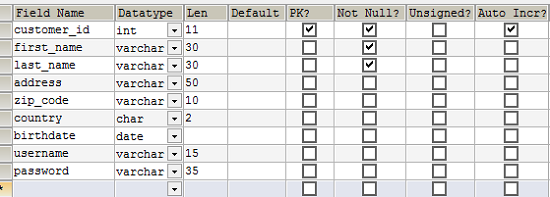
Обратите внимание, что выбран флажок первичного ключа (PK) для поля customer_id. Поле customer_id является первичным ключом. Также выбран флажок Auto Incr, что означает, что база данных будет автоматически подставлять уникальное числовое значение, которое, начиная с нуля, будет каждый раз увеличиваться на одну единицу.
Проектируем таблицу заказов.
Какие минимальные блоки информации, необходимые нам, относятся к заказу?
- order_id (primary key) – идентификатор заказа
- order_date – дата и время заказа
- customer – клиент, который сделал заказ

Проект таблицы. Поле customer является ссылкой (внешним ключом) для поля customer_id в таблице клиентов.
Эти две таблицы (клиентов и заказов) связаны потому, что поле customer в таблице заказов ссылается на первичный ключ (customer_id) таблицы клиентов. Такая связь называется связью по внешнему ключу. Вы должны представлять себе внешний ключ как простую копию (копию значения) первичного ключа другой таблицы. В нашем случае значение поля customer_id из таблицы клиентов копируется в таблицу заказов при вставке каждой записи. Таким образом, у нас каждый заказ привязан к клиенту. И заказов у каждого клиента может быть много, как и говорилось выше.
Создание связи по внешнему ключу.
Вы можете задаться вопросом: “Каким образом я могу убедиться или как я могу увидеть, что поле customer в таблице заказов ссылается на поле customer_id в таблице клиентов”. Ответ прост – вы не можете сделать этого потому, что я еще не показал вам как создать связь.
Ниже – окно SQLyog с окном, которое я использовал для создания связи между таблицами.
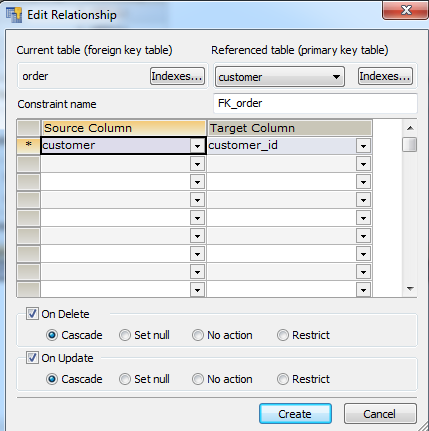
Создание связи по внешнему ключу между таблицами заказов и клиентов.
В окне выше вы можете видеть, как поле customer таблицы заказов слева связывается с первичным ключом (customer_id) таблицы клиентов справа.
Теперь, когда вы посмотрите на данные, которые могли бы быть в таблицах, вы увидите, что две таблицы связаны.
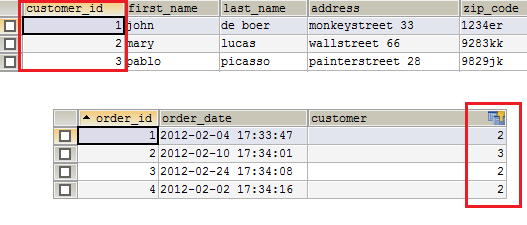
Заказы связаны с клиентами через поле customer, которое ссылается на таблицу клиентов.
На изображении вы видите, что клиент mary поместила три заказа, клиент pablo поместил один, а клиент john – ни одного.
Вы можете спросить: “А что же именно заказали все эти люди?” Это хороший вопрос. Вы возможно ожидали увидеть заказанные товары в таблице заказов. Но это плохой пример проектирования. Как бы вы поместили множественные продукты в единственную запись? Товары – это отдельные сущности, которые должны храниться в отдельной таблице. И связь между таблицами заказов и товаров будет являться связью один-ко-многим.
Создание диаграммы сущность-связь.
Ранее вы узнали как записи из разных таблиц связываются друг с другом в реляционных базах данных. Перед созданием и связыванием таблиц важно, чтобы вы подумали о сущностях, которые существуют в вашей системе (для которой вы создаете базу данных) и решили каким образом эти сущности бы связывались друг с другом. В проектировании баз данных сущности и их отношения обычно предоставляются в диаграмме сущность-связь (англ. entity-relationship diagram, ERD). Данная диаграмма является результатом процесса проектирования базы данных.
Сущности.
В контексте проектирования баз данных сущность – это нечто, что заслуживает своей собственной таблицы в модели вашей базы данных. Когда вы проектируете базу данных, вы должны определить эти сущности в системе, для которой вы создаете базу данных.
Давайте возьмем интернет-магазин для примера. Интернет-магазин продает товары. Товар мог бы стать очевидной сущностью в системе интернет-магазина. Товары заказываются клиентами. Вот мы с вами и увидели еще две очевидных сущности: заказы и клиенты. Заказ оплачивается клиентом... это интересно. Мы собираемся создавать отдельную таблицу для платежей в базе данных нашего интернет-магазина? Возможно. Но разве платежи – это минимальный блок информации, который относится к заказам? Это тоже возможно.
Если вы не уверены, то просто подумайте о том, какую информацию о платежах вы хотите хранить. Возможно, вы захотите хранить метод платежа или дату платежа. Но это все еще минимальные блоки информации, которые могли бы относиться к заказу. Можно изменить формулировки. Метод платежа — метод платежа заказа. Дата платежа – дата платежа заказа. Таким образом, я не вижу необходимости выносить платежи в отдельную таблицу, хотя концептуально вы бы могли выделить платежи как сущность, т.к. вы могли бы рассматривать платежи как контейнер информации (метод платежа, дата платежа).
Как вы видите определение того, какие сущности имеет ваша система – это немного интеллектуальный процесс, который требует некоторого опыта и часто – это предмет для внесения изменений, пересмотров, раздумий...
Связь один-ко-многим.
Когда одна запись в таблице А может быть связана с 0, 1 или множеством записей в таблице B, вы имеете дело со связью один-ко-многим. В реляционной модели данных связь один-ко-многим использует две таблицы.
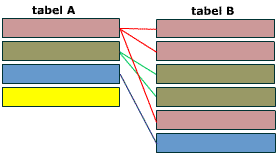
Схематическое представление связи один-ко-многим. Запись в таблице А имеет 0, 1 или множество ассоциированных ей записей в таблице B.
Как опознать связь один-ко-многим?
Если у вас есть две сущности спросите себя:
- Сколько объектов из B могут относится к объекту A?
- Сколько объектов из A могут относиться к объекту из B?
Если на первый вопрос ответ – множество, а на второй – один (или возможно, что ни одного), то вы имеете дело со связью один-ко-многим.
Некоторые примеры связи один-ко-многим:
- Машина и ее части. Каждая часть машины единовременно принадлежит только одной машине, но машина может иметь множество частей.
- Кинотеатры и экраны. В одном кинотеатре может быть множество экранов, но каждый экран принадлежит только одному кинотеатру.
- Диаграмма сущность-связь и ее таблицы. Диаграмма может иметь больше, чем одну таблицу, но каждая из этих таблиц принадлежит только одной диаграмме.
- Дома и улицы. На улице может быть несколько домов, но каждый дом принадлежит только одной улице.
Связь многие-ко-многим.
Связь многие-ко-многим – это связь, при которой множественным записям из одной таблицы (A) могут соответствовать множественные записи из другой (B). Примером такой связи может служить школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, а каждый учащийся может обучаться несколькими учителями.
Обратите внимание, что при проектировании базы данных вы должны спросить себя не о том, существуют ли определенные связи в данный момент, а о том, возможно ли существование связей вообще, в перспективе. Если в настоящий момент все поставщики предоставляют множество видов пива, но каждый вид пива предоставляется только одним поставщиком, то вы можете подумать, что это связь один-ко-многим, но... Не торопитесь реализовывать связь один-ко-многим в этой ситуации. Существует высокая вероятность того, что в будущем два или более поставщиков будут поставлять один и тот же вид пива и когда это случится ваша база данных — со связью один-ко-многим между поставщиками и видами пива – не будет подготовлена к этому.
Создание связи многие-ко-многим.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы – “источника” и одна соединительная таблица. Первичный ключ соединительной таблицы A_B – составной. Она состоит из двух полей, двух внешних ключей, которые ссылаются на первичные ключи таблиц A и B.
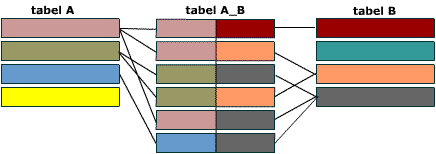
Все первичные ключи должны быть уникальными. Это подразумевает и то, что комбинация полей A и B должна быть уникальной в таблице A_B.
Пример проект базы данных ниже демонстрирует вам таблицы, которые могли бы существовать в связи многие-ко-многим между бельгийскими брендами пива и их поставщиками в Нидерландах. Обратите внимание, что все комбинации beer_id и distributor_id уникальны в соединительной таблице.
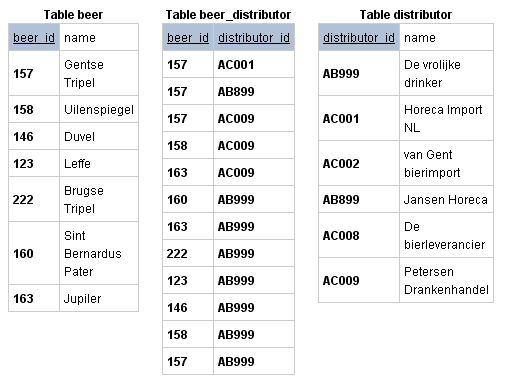
Таблицы выше связывают поставщиков и пиво связью многие-ко-многим, используя соединительную таблицу. Обратите внимание, что пиво 'Gentse Tripel' (157) поставляют Horeca Import NL (157, AC001) Jansen Horeca (157, AB899) и Petersen Drankenhandel (157, AC009). И vice versa, Petersen Drankenhandel является поставщиком 3 видов пива из таблицы, а именно: Gentse Tripel (157, AC009), Uilenspiegel (158, AC009) и Jupiler (163, AC009).
Еще обратите внимание, что в таблицах выше поля первичных ключей окрашены в синий цвет и имеют подчеркивание. В модели проекта базы данных первичные ключи обычно подчеркнуты. И снова обратите внимание, что соединительная таблица beer_distributor имеет первичный ключ, составленный из двух внешних ключей. Соединительная таблица всегда имеет составной первичный ключ.
Есть еще одна важная вещь которую нужно знать. Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: поставщики пива и пиво – имеют связь один-ко-многим с соединительной таблицей.
Связь один-к-одному.
В связи один-к-одному каждый блок сущности A может быть ассоциирован с 0, 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью.
В редких случаях связь один-к-одному моделируется используя две таблицы. Такой вариант иногда необходим, чтобы преодолеть ограничения РСУБД или с целью увеличения производительности (например, иногда — это вынесение поля с типом данных blob в отдельную таблицу для ускорения поиска по родительской таблице). Или порой вы можете решить, что вы хотите разделить две сущности в разные таблицы в то время, как они все еще имеют связь один-к-одному. Но обычно наличие двух таблиц в связи один-к-одному считается дурной практикой.
Примеры связи один-к-одному.
Люди и их паспорта. Каждый человек в стране имеет только один действующий паспорт и каждый паспорт принадлежит только одному человеку.
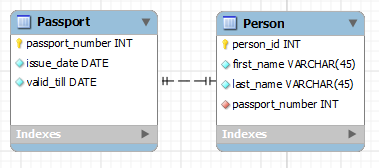
Проект реляционной базы данных – это коллекция таблиц, которые перелинковываются (связываются) первичными и внешними ключами. Реляционная модель данных включает в себя ряд правил, которые помогают вам создать верные связи между таблицами. Эти правила называются “нормальными формами”.
Нормализация баз данных.
Указания для правильного проектирования реляционных баз данных изложены в реляционной модели данных. Они собраны в 5 групп, которые называются нормальными формами. Первая нормальная форма представляет самый низкий уровень нормализации баз данных. Пятый уровень представляет высший уровень нормализации.
Нормальные формы – это рекомендации по проектированию баз данных. Вы не обязаны придерживаться всех пяти нормальных форм при проектировании баз данных. Тем не менее, рекомендуется нормализовать базу данных в некоторой степени потому, что этот процесс имеет ряд существенных преимуществ с точки зрения эффективности и удобства обращения с вашей базой данных.
- В нормализованной структуре базы данных вы можете производить сложные выборки данных относительно простыми SQL-запросами.
- Целостность данных. Нормализованная база данных позволяет надежно хранить данные.
- Нормализация предотвращает появление избыточности хранимых данных. Данные всегда хранятся только в одном месте, что делает легким процесс вставки, обновления и удаления данных. Есть исключение из этого правила. Ключи, сами по себе, хранятся в нескольких местах потому, что они копируются как внешние ключи в другие таблицы.
- Масштабируемость – это возможность системы справляться с будущим ростом. Для базы данных это значит, что она должна быть способна работать быстро, когда число пользователей и объемы данных возрастают. Масштабируемость – это очень важная характеристика любой модели базы данных и для РСУБД.
Вот некоторые из основных пунктов, которые связаны с нормализацией баз данных:
- Упорядочивание данных в логические группы или наборы.
- Нахождение связей между наборами данных. Вы уже видели примеры связей один-ко-многим и многие-ко-многим.
- Минимизация избыточности данных.
Очень малое количество баз данных следуют всем пяти нормальным формам, предоставленным в реляционной модели данных. Обычно базы данных нормализуются до второй или третьей нормальной формы. Четвертая и пятая формы используются редко.
Первая нормальная форма (1НФ).
Первая нормальная форма гласит, что таблица базы данных – это представление сущности вашей системы, которую вы создаете. Примеры сущностей: заказы, клиенты, заказ билетов, отель, товар и т.д. Каждая запись в базе данных представляет один экземпляр сущности. Например, в таблице клиентов каждая запись представляет одного клиента.
- Первичный ключ.
Правило: каждая таблица имеет первичный ключ, состоящий из наименьшего возможного количества полей.
Как вы знаете, первичный ключ может состоять из нескольких полей. Вы, к примеру, можете выбрать имя и фамилию в качестве первичного ключа (и надеяться, что эта комбинация будет уникальной всегда). Будет намного более хорошим выбором номер соц. страхования в качестве первичного ключа, т.к. это единственное поле, которое уникальным образом идентифицирует человека. Еще лучше, когда нет очевидного кандидата на звание первичного ключа, создайте суррогатный первичный ключ в виде числового автоинкрементного поля.
- Атомарность.
Правило: поля не имеют дубликатов в каждой записи и каждое поле содержит только одно значение.
- Порядок записей не должен иметь значение.
Правило: порядок записей таблицы не должен иметь значения.
Вы можете быть склонны использовать порядок записей в таблице клиентов для определения того, какой из клиентов зарегистрировался первым. Для этих целей вам лучше создать поля даты и времени регистрации клиентов. Порядок записей будет неизбежно меняться, когда клиенты будут удаляться, изменяться или добавляться. Вот почему вам никогда не следует полагаться на порядок записей в таблице.
Вторая нормальная форма (2НФ).
Для того, чтобы база данных была нормализована согласно второй нормальной форме, она должна быть нормализована согласно первой нормальной форме. Вторая нормальная форма связана с избыточностью данных.
- Избыточность данных.
Правило: поля с не первичным ключом не должны быть зависимы от первичного ключа.
Может звучать немного заумно. А означает это то, что вы должны хранить в таблице только данные, которые напрямую связаны с ней и не имеют отношения к другой сущности. Следование второй нормальной форме – это вопрос нахождения данных, которые часто дублируются в записях таблицы и которые могут принадлежать другой сущности.
Насколько строго вы подходите к созданию ваших таблиц – решать вам и зависит от конкретной ситуации. Если вы планируете хранить огромное количество единиц автомобилей в системе и вы хотите иметь возможность производить поиск по цвету (color), то было бы мудрым решением выделить цвета в отдельную таблицу так, чтобы они не дублировались.
Существует другой случай, когда вы можете захотеть выделить цвета в отдельную таблицу. Если вы хотите позволить работникам компании вносить данные о новых автомобилях вы захотите, чтобы они имели возможно выбирать цвет машины из заранее заданного списка. В этом случае вы захотите хранить все возможные цвета в вашей базе данных. Даже если еще нет машин с таким цветом, вы захотите, чтобы эти цвета присутствовали в базе данных, чтобы работники могли их выбирать. Это определенно тот случай, когда вам нужно выделить цвета в отдельную таблицу.
Третья нормальная форма (3НФ).
Третья нормальная форма связана с транзитивными зависимостями. Транзитивные зависимости между полями базы данных существует тогда, когда значения не ключевых полей зависят от значений других не ключевых полей. Чтобы база данных была в третьей нормальной форме, она должна быть во второй нормальной форме.
- Транзитивные зависимости.
Правило: не может быть транзитивных зависимостей между полями в таблице.
Таблица клиентов (мои клиенты – игроки немецкой и французской футбольной команды) ниже содержит транзитивные зависимости.
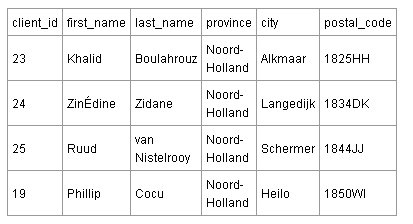
В этой таблице не все поля зависят исключительно от первичного ключа. Существует отдельная связь между полем postal_code и полями города (city) и провинции (province). В Нидерландах оба значение: город и провинция – определяются почтовым кодом, индексом. Таким образом, нет необходимости хранить город и провинцию в клиентской таблице. Если вы знаете почтовый код, то вы уже знаете город и провинцию.
Такой транзитивной зависимости следует избегать, если вы хотите, чтобы ваша модель базы данных была в третьей нормальной форме.
В данном случае устранение транзитивной зависимости из таблицы может быть достигнуто путем удаления полей города и провинции из таблицы и хранение их в отдельной таблице, содержащей почтовый код (первичный ключ), имя провинции и имя города. Получение комбинации почтовый код-город-провинция для целой страны может быть весьма нетривиальным занятием. Вот почему такие таблицы зачастую продаются.
Третья нормальная форма гласит, что вы не должны хранить данные в таблице, которые могут быть получены из других (не ключевых) полей таблицы.
Третья нормальная форма не всегда используется при проектировании баз данных. Когда разрабатываете базу данных вы всегда должны сравнивать преимущества от более высокой нормальной формы в сравнении с объемом работ, которые требуются для применения третьей нормальной формы и поддержания данных в таком состоянии.
Хранение данных, воспроизводимых из существующих, обычно плохая идея.
Source: Habr