Обзор движка, механизмов времени выполнения, стека вызовов
- Обзор
Почти все слышали, в самых общих чертах, о JS-движке V8, и большинству разработчиков известно, что JavaScript - однопоточный язык, или то, что он использует очередь функций обратного вызова.
Здесь мы поговорим, на довольно высоком уровне, о выполнении JS-кода. Зная о том, что, на самом деле, происходит при выполнении JavaScript, вы сможете писать более качественные программы, которые выполняются без "подвисаний" и разумно используют имеющиеся API.
- Движок JavaScript
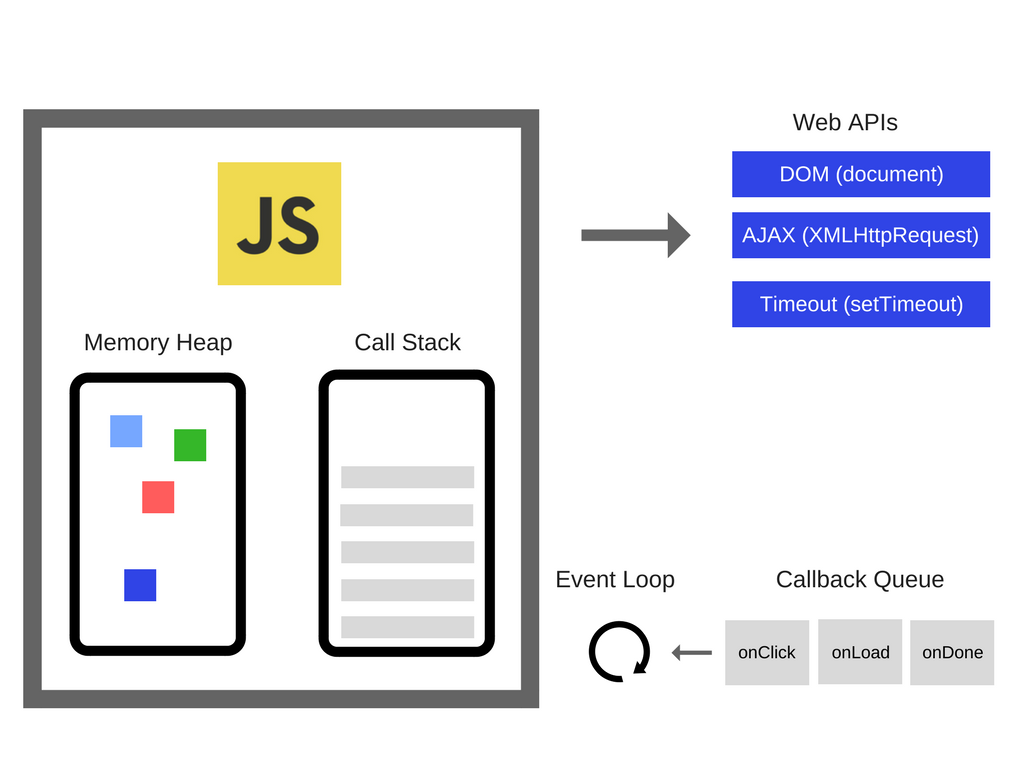
V8 от Google - это широко известный JS-движок. Он используется, например, в браузере Chrome и в Node.js. Вот как его, очень упрощённо, можно представить:
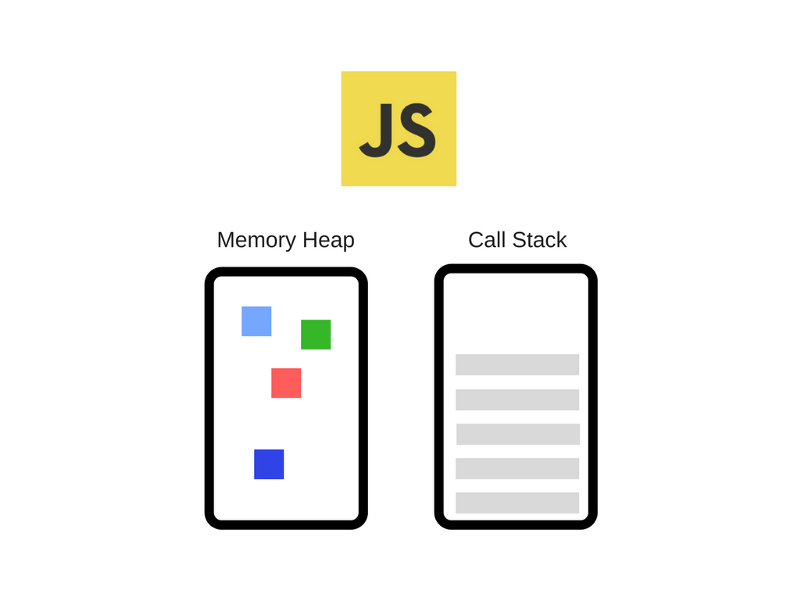
На нашей схеме движок представлен состоящим из двух основных компонентов:
- Куча (Memory Heap) - то место, где происходит выделение памяти.
- Стек вызовов (Call Stack) - то место, куда в процессе выполнения кода попадают так называемые стековые кадры.
- Механизмы времени выполнения
Если говорить о применении JavaScript в браузере, то здесь существуют API, например, что-то вроде функции setTimeout, которые использует практически каждый JS-разработчик. Однако, эти API предоставляет не движок. Откуда же они берутся? Оказывается, что реальность выглядит немного сложнее, чем может показаться на первый взгляд.
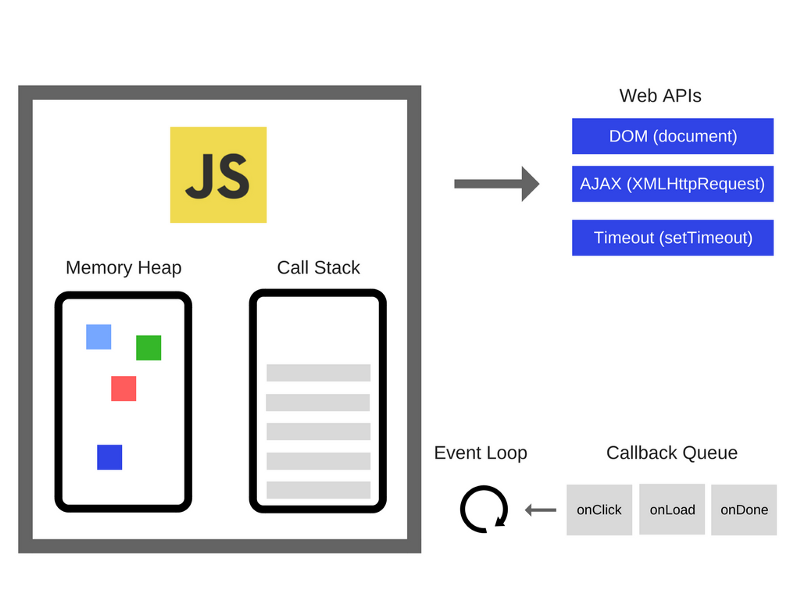
Итак, помимо движка у нас есть ещё очень много всего. Скажем - так называемые Web API, которые предоставляет нам браузер - средства для работы с DOM, инструменты для выполнения AJAX-запросов, нечто вроде функции setTimeout, и многое другое.
- Стек вызовов
JavaScript - однопоточный язык программирования. Это означает, что у него один стек вызовов. Таким образом, в некий момент времени он может выполнять лишь какую-то одну задачу.
Стек вызовов - это структура данных, которая, говоря упрощённо, записывает сведения о месте в программе, где мы находимся. Если мы переходим в функцию, мы помещаем запись о ней в верхнюю часть стека. Когда мы из функции возвращаемся, мы вытаскиваем из стека самый верхний элемент и оказываемся там, откуда вызывали эту функцию. Это - всё, что умеет стек.
Рассмотрим пример. Взгляните на следующий код:
function multiply(x, y) {
return x * y;
}
function printSquare(x) {
var s = multiply(x, x);
console.log(s);
}
printSquare(5);
Когда движок только начинает выполнять этот код, стек вызовов пуст. После этого происходит следующее:
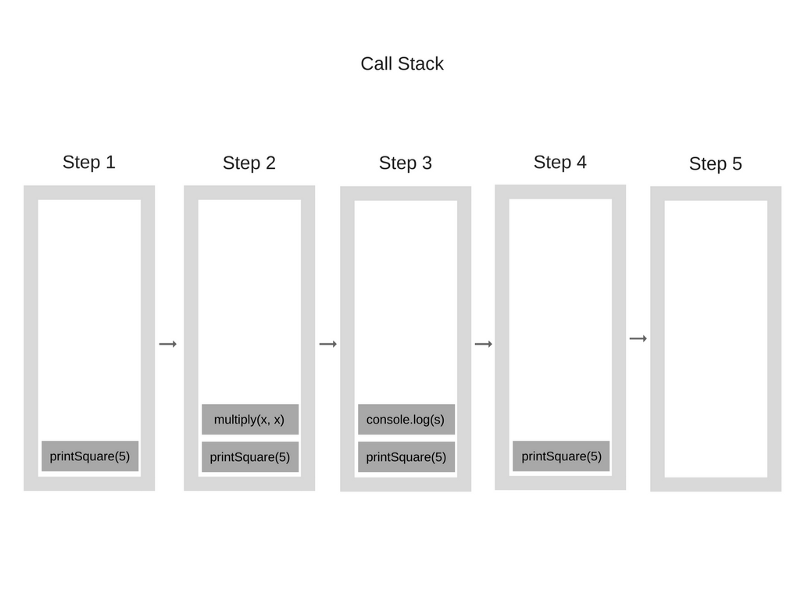
Каждая запись в стеке вызовов называется стековым кадром.
На механизме анализа стековых кадров основана информация о стеке вызовов, трассировка стека, выдаваемая при возникновении исключения. Трассировка стека представляет собой состояние стека в момент исключения. Взгляните на следующий код:
function foo() {
throw new Error('SessionStack will help you resolve crashes :)');
}
function bar() {
foo();
}
function start() {
bar();
}
start();
Если выполнить это в Chrome (предполагается, что код находится в файле foo.js), мы увидим следующие сведения о стеке:

Если будет достигнут максимальный размер стека, возникнет так называемое переполнение стека. Произойти такое может довольно просто, например, при необдуманном использовании рекурсии. Взгляните на этот фрагмент кода:
function foo() {
foo();
}
foo();
Когда движок приступает к выполнению этого кода, всё начинается с вызова функции foo. Это - рекурсивная функция, которая не содержит условия прекращения рекурсии. Она бесконтрольно вызывает сама себя. В результате на каждом шаге выполнения в стек вызовов снова и снова добавляется информация об одной и той же функции. Выглядит это примерно так:
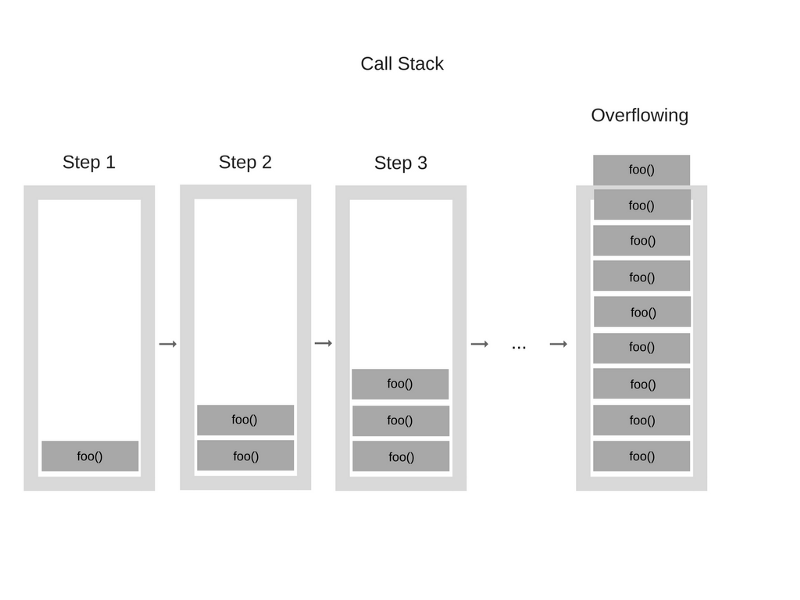
В определённый момент, однако, объём данных о вызовах функции превысит размер стека вызовов и браузер решит вмешаться, выдав ошибку:
![]()
Модель выполнения кода в однопоточном режиме облегчает жизнь разработчика. Ему не нужно принимать во внимание сложные схемы взаимодействия программных механизмов, вроде возможности взаимной блокировки потоков, которые возникают в многопоточных окружениях.
Однако, и у исполнения кода в однопоточном режиме тоже есть определённые ограничения. Учитывая то, что у JavaScript имеется один стек вызовов, поговорим о том, что происходит, когда программа "тормозит".
- Параллельное выполнение кода и цикл событий
Что происходит, когда в стеке вызовов имеется функция, на выполнение которой нужно очень много времени? Например, представьте, что вам надо выполнить какое-то сложно преобразование изображения с помощью JavaScript в браузере.
"А в чём тут проблема?", - спросите вы. Проблема заключается в том, что до тех пор, пока в стеке вызовов имеется выполняющаяся функция, браузер не может выполнять другие задачи - он оказывается заблокированным. Это означает, что браузер не может выводить ничего на экран, не может выполнять другой код. Он просто останавливается. Подобные эффекты, например, несовместимы с интерактивными интерфейсами.
Однако, это - не единственная проблема. Если браузер начинает заниматься обработкой тяжёлых задач, он может на достаточно долгое время перестать реагировать на какие-либо воздействия. Большинство браузеров в подобной ситуации выдают ошибку, спрашивая пользователя о том, хочет ли он завершить выполнение сценария и закрыть страницу.
Пользователям подобные вещи точно не понравятся.
Итак, как же выполнять тяжёлые вычисления, не блокируя пользовательский интерфейс и не подвешивая браузер? Решение этой проблемы заключается в использовании асинхронных функций обратного вызова.
О внутреннем устройстве V8 и оптимизации кода
- О JS-движках
JavaScript-движок - это программа, или, другими словами, интерпретатор, выполняющий код, написанный на JavaScript. Движок может быть реализован с использованием различных подходов: в виде обычного интерпретатора, в виде динамического компилятора (или JIT-компилятора), который, перед выполнением программы, преобразует исходный код на JS в байт-код некоего формата.
Вот список популярных реализаций JavaScript-движков:
- V8 - движок с открытым исходным кодом, написан на C++, его разработкой занимается Google.
- Rhino - этот движок с открытым кодом поддерживает Mozilla Foundation, он полностью написан на Java.
- SpiderMonkey - это самый первый из появившихся JS-движков, который в прошлом применялся в браузере Netscape Navigator, а сегодня - в Firefox.
- JavaScriptCore - ещё один движок с открытым кодом, известный как Nitro и разрабатываемый Apple для браузера Safari.
- KJS - JS-движок KDE, который разработал Гарри Портен для браузера Konqueror, входящего в проект KDE.
- Chakra (JScript9) - движок для Internet Explorer.
- Chakra (JavaScript) - движок для Microsoft Edge.
- Nashorn - движок с открытым кодом, являющийся частью OpenJDK, которым занимается Oracle.
- JerryScript - легковесный движок для интернета вещей.
В этом материале мы остановимся на особенностях V8.
- Почему был создан движок V8?
Движок с открытым кодом V8 был создан компанией Google, он написан на C++. Движок используется в браузере Google Chrome. Кроме того, что отличает V8 от других движков, он применяется в популярной серверной среде Node.js.
При проектировании V8 разработчики задались целью улучшить производительность JavaScript в браузерах. Для того, чтобы добиться высокой скорости выполнения программ, V8 транслирует JS-код в более эффективный машинный код, не используя интерпретатор. Движок компилирует JavaScript-код в машинные инструкции в ходе исполнения программы, реализуя механизм динамической компиляции, как и многие современные JavaScript-движки, например, SpiderMonkey и Rhino (Mozilla). Основное различие заключается в том, что V8 не использует при исполнении JS-программ байт-код или любой промежуточный код.
- О двух компиляторах, которые использовались в V8
Внутреннее устройство V8 изменилось с выходом версии 5.9, которая появилась совсем недавно. До этого же он использовал два компилятора:
- full-codegen - простой и очень быстрый компилятор, который выдаёт сравнительно медленный машинный код.
- Crankshaft - более сложный оптимизирующий JIT-компилятор, который генерирует хорошо оптимизированный код.
Внутри движка используются несколько потоков:
- Главный поток, который занимается тем, что от него можно ожидать: читает исходный JS-код, компилирует его и выполняет.
- Поток компиляции, который занимается оптимизацией кода в то время, когда выполняется главный поток.
- Поток профилировщика, который сообщает системе о том, в каких методах программа тратит больше всего времени, как результат, Crankshaft может эти методы оптимизировать.
- Несколько потоков, которые поддерживают механизм сборки мусора.
При первом исполнении JS-кода V8 задействует компилятор full-codegen, который напрямую, без каких-либо дополнительных трансформаций, транслирует разобранный им JavaScript-код в машинный код. Это позволяет очень быстро приступить к выполнению машинного кода. Обратите внимание на то, что V8 не использует промежуточное представление программы в виде байт-кода, таким образом, устраняя необходимость в интерпретаторе.
После того, как код какое-то время поработает, поток профилировщика соберёт достаточно данных для того, чтобы система могла понять, какие методы нужно оптимизировать.
Далее, в другом потоке, начинается оптимизация с помощью Crankshaft. Он преобразует абстрактное синтаксическое дерево JavaScript в высокоуровневое представление, использующее модель единственного статического присваивания (Static Single-Assignment, SSA). Это представление называется Hydrogen. Затем Crankshaft пытается оптимизировать граф потока управления Hydrogen. Большинство оптимизаций выполняется на этом уровне.
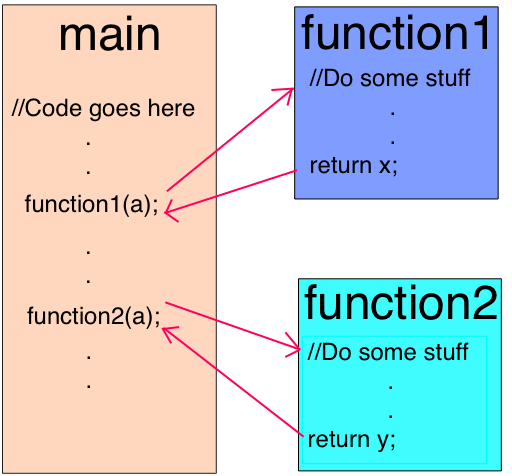
- Встраивание кода
Первая оптимизация программы заключается в заблаговременном встраивании в места вызовов как можно большего объёма кода. Встраивание кода - это процесс замены команды вызова функции (строки, где вызывается функция) на её тело. Этот простой шаг позволяет сделать следующие оптимизации более результативными:
- Скрытые классы
JavaScript - это язык, основанный на прототипах: здесь нет классов. Объекты здесь создаются с использованием процесса клонирования. Кроме того, JS - это динамический язык программирования, это значит, что, после создания экземпляра объекта, к нему можно добавлять новые свойства и удалять из него существующие.
Большинство JS-интерпретаторов используют структуры, напоминающие словари (основанные на использовании хэш-функций), для хранения сведений о месте расположения значений свойств объектов в памяти. Использование подобных структур делает извлечение значений свойств в JavaScript более сложной задачей, чем в нединамических языках, таких, как Java и C#. В Java, например, все свойства объекта определяются не изменяющейся после компиляции программы схемой объекта, их нельзя динамически добавлять или удалять (надо отметить, что в C# есть динамический тип, но тут мы можем не обращать на это внимание). Как результат, значения свойств (или указатели на эти свойства) могут быть сохранены, с фиксированным смещением, в виде непрерывного буфера в памяти. Шаг смещения можно легко определить, основываясь на типе свойства, в то время как в JavaScript это невозможно, так как тип свойства может меняться в процессе выполнения программы.
Так как использование словарей для выяснения адресов свойств объекта в памяти очень неэффективно, V8 использует вместо этого другой метод: скрытые классы. Скрытые классы похожи на обычные классы в типичном объектно-ориентированном языке программирования, вроде Java, за исключением того, что создаются они во время выполнения программы. Посмотрим, как всё это работает, на следующем примере:
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
Когда происходит вызов new Point(1, 2), V8 создаёт скрытый класс C0:
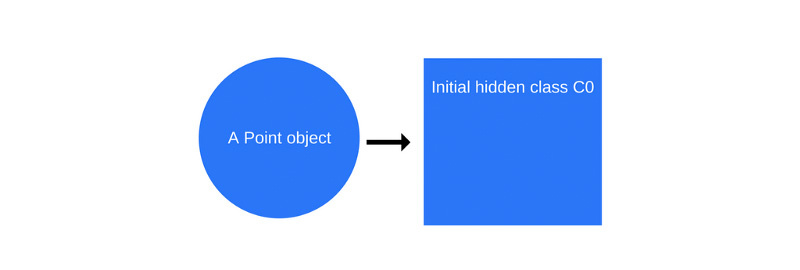
Пока, ещё до выполнения конструктора, у объекта Point нет свойств, поэтому класс C0 пуст.
Как только будет выполнена первая команда в функции Point, V8 создаст второй скрытый класс, C1, который основан на C0. C1 описывает место в памяти (относительно указателя объекта), где можно найти свойство x. В данном случае свойство x хранится по смещению 0, что означает, что если рассматривать объект Point в памяти как непрерывный буфер, первое смещение соответствует свойству x. Кроме того, V8 добавит в класс C0 сведения о переходе к классу C1, где указывается, что если к объекту Point будет добавлено свойство x, скрытый класс нужно изменить с C0 на C1. Скрытый класс для объекта Point, как показано на рисунке ниже, теперь стал классом С1.
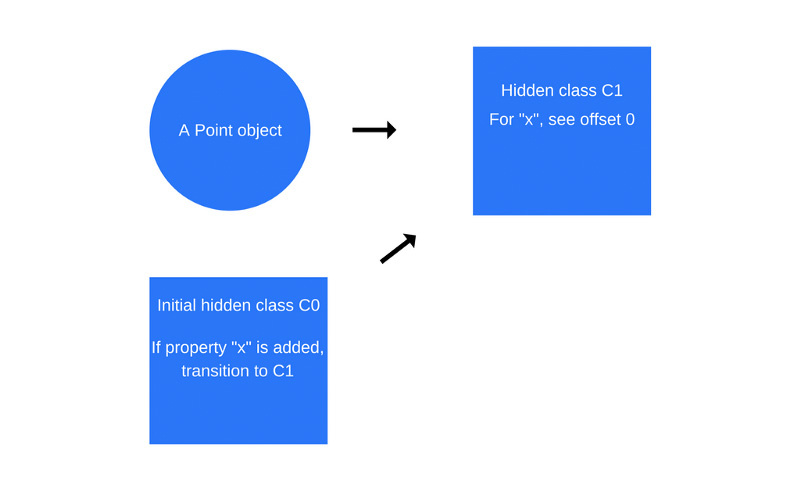
Каждый раз, когда к объекту добавляется новое свойство, в старый скрытый класс добавляются сведения о переходе к новому скрытому классу. Переходы между скрытыми классами важны, так как они позволяют объектам, которые создаются одинаково, иметь одни и те же скрытые классы. Если два объекта имеют общий скрытый класс и к ним добавляется одно и то же свойство, переходы обеспечат то, что оба объекта получат одинаковый новый скрытый класс и весь оптимизированный код, который идёт вместе с ним.
Этот процесс повторяется при выполнении команды this.y = y (опять же, делается это внутри функции Point, после вышеописанной команды по добавлению свойства x).
Тут создаётся новый скрытый класс, C2, а в класс C1 добавляются сведения о переходе, где указывается, что если к объекту Point добавляется свойство y (при этом речь идёт об объекте, который уже содержит свойство x), тогда скрытый класс объекта должен измениться на C2.
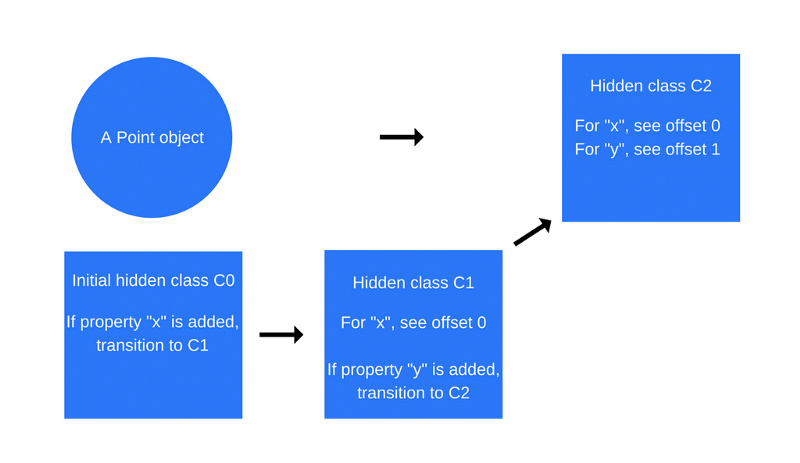
Переходы между скрытыми классами зависят от порядка, в котором к объекту добавляются свойства. Взгляните на этот пример кода:
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
p1.a = 5;
p1.b = 6;
var p2 = new Point(3, 4);
p2.b = 7;
p2.a = 8;
В подобной ситуации можно предположить, что у объектов p1 и p2 будет один и тот же скрытый класс и одно и то же дерево переходов скрытых классов. Однако, на самом деле это не так. В объект p1 первым добавляется свойство a, а затем - свойство b. В объект p2 сначала добавляют свойство b, а затем - a. В результате объекты p1 и p2 будут иметь различные скрытые классы - результат различных путей переходов между скрытыми классами. В подобных случаях гораздо лучше инициализировать динамические свойства в одном и том же порядке для того, чтобы скрытые классы могли быть использованы повторно.
- Встроенные кэши
V8 использует и другую технику для оптимизации выполнения динамически типизированных языков, называемую встроенным кэшем вызовов. Встроенное кэширование основано на наблюдении, которое заключается в том, что повторяющиеся обращения к одному и тому же методу имеют тенденцию происходить с использованием объектов одного типа.
Итак, как же всё это работает? V8 поддерживает кэш типов объектов, которые мы передали в качестве параметра недавно вызванным методам, и использует эту информацию для того, чтобы сделать предположение о типах объектов, которые будут переданы как параметры в будущем. Если V8 смог сделать правильное предположение о типе объекта, который будет передан методу, он может пропустить процесс выяснения того, как получать доступ к свойствам объекта, а, вместо этого, использовать сохранённую информацию из предыдущих обращений к скрытому классу объекта.
Как связаны концепции скрытых классов и встроенных кэшей вызовов? Когда метод вызывается для некоего объекта, движок V8 должен обратиться к скрытому классу этого объекта для того, чтобы определить смещение для доступа к конкретному свойству. После двух успешных обращений одного и того же метода к одному и тому же скрытому классу, V8 опускает операцию обращения к скрытому классу и просто добавляет сведения о смещении свойства к самому указателю объекта. Выполняя вызовов этого метода в будущем, V8 предполагает, что скрытый класс не менялся и идёт прямо по адресу памяти для конкретного свойства, используя смещение, сохранённое после предыдущих обращений к скрытому классу. Это очень сильно увеличивает скорость выполнения кода.
Встроенное кэширование вызовов, кроме того, является причиной того, почему так важно, чтобы объекты одного и того же типа использовали общие скрытые классы. Если вы создаёте два объекта одинакового типа, но с разными скрытыми классами (как сделано в примере выше), V8 не сможет использовать встроенное кэширование, так как, даже хотя объекты имеют один и тот же тип, в соответствующих им скрытых классах назначено разное смещение их свойствам.

- Компиляция в машинный код
Как только граф Hydrogen оптимизирован, Crankshaft переводит его в низкоуровневое представление, которое называется Lithium. Большинство реализаций Lithium зависимо от архитектуры системы. На этом уровне, например, происходит выделение регистров.
В итоге Lithium-представление компилируется в машинный код. Затем происходит то, что называется замещением в стеке (On-Stack Replacement, OSR). Перед компиляцией и оптимизацией методов, в которых программа тратит много времени, нужно будет поработать с их неоптимизированными вариантами. Затем, не прерывая работу, V8 трансформирует контекст (стек, регистры) таким образом, чтобы можно было переключиться на оптимизированную версию кода. Это очень сложная задача, учитывая то, что помимо других оптимизаций, V8 изначально выполняет встраивание кода. V8 - не единственный движок, способный это сделать.
Как быть, если оптимизация оказалась неудачной? От этого есть защита - так называемая деоптимизация. Она направлена на обратную трансформацию, возвращающую систему к использованию неоптимизированного кода в том случае, если предположения, сделанные движком и положенные в основу оптимизации, больше не соответствуют действительности.
- Сборка мусора
Для сборки мусора V8 использует традиционный генеалогический подход "пометь и выброси" (mark-and-sweep) для маркировки и очистки предыдущих поколений кода. Фаза маркировки предполагает остановку выполнения JavaScript. Для того, чтобы контролировать нагрузку на систему, создаваемую сборщиком мусора и сделать выполнение кода более стабильным, V8 использует инкрементный алгоритм маркирования: вместо того, чтобы обходить всю кучу, он пытается пометить всё, что сможет, обходя лишь часть кучи. Затем нормальное выполнение кода возобновляется. Следующий проход сборщика мусора по куче начинается там, где закончился предыдущий. Это позволяет добиться очень коротких пауз в ходе обычного выполнения кода. Как уже было сказано, фазой очистки памяти занимаются отдельные потоки.
- Ignition и TurboFan
С выходом в этом году V8 версии 5.9. был представлен и новый конвейер выполнения кода. Этот конвейер позволяет достичь ещё большего улучшения производительности и значительной экономии памяти, причём, не в тестах, а в реальных JavaScript-приложениях. Новая система построена на базе интерпретатора Ingnition и новейшего оптимизирующего компилятора TurboFan.
С выходом V8 5.9 full-codegen и Crankshaft (технологии, которые использовались в V8 с 2010-го года) больше применяться не будут. Команда V8 развивает новые средства, стараясь не отстать от новых возможностей JavaScript и внедрить оптимизации, необходимые для поддержки этих возможностей. Переход на новые технологии и отказ от поддержки старых механизмов означает развитие V8 в сторону более простой и хорошо управляемой архитектуры.
Эти улучшения - лишь начало. Новый конвейер выполнения кода на основе Ignition и TurboFan открывает путь к дальнейшим оптимизациям, которые улучшат производительность JavaScript и сделают V8 экономичнее.
Мы рассмотрели некоторые особенности V8, а теперь приведём несколько советов по оптимизации кода. На самом деле, кстати, всё это вполне можно вывести из того, о чём мы говорили выше.
- Подходы к оптимизации JavaScript-кода для V8
- Порядок свойств объектов. Всегда инициализируйте свойства объектов в одном и том же порядке. Нужно это для того, чтобы одинаковые объекты использовали одни и те же скрытые классы, и, как следствие, оптимизированный код.
- Динамические свойства. Добавление свойств к объектам после создания экземпляра объекта приведёт к изменению скрытого класса и к замедлению методов, которые были оптимизированы для скрытого класса, используемого объектами ранее. Вместо добавления свойств динамически, назначайте их в конструкторе объекта.
- Методы. Код, который несколько раз вызывает один и тот же метод, будет выполняться быстрее, чем код, который вызывает несколько разных методов по одному разу (из-за встроенных кэшей).
- Массивы. Избегайте разреженных массивов, ключи которых не являются последовательными числами. Разреженный массив, то есть массив, некоторые из элементов которого отсутствуют, будет обрабатываться системой как хэш-таблица. Для доступа к элементам такого массива требуется больше вычислительных ресурсов. Кроме того, постарайтесь избежать заблаговременного выделения памяти под большие массивы. Лучше, если их размер будет увеличиваться по мере надобности. И, наконец, не удаляйте элементы в массивах. Из-за этого они превращаются в разреженные массивы.
- Числа. V8 представляет числа и указатели на объекты, используя 32 бита. Он задействует один бит для того, чтобы определить, является ли некое 32-битное значение указателем на объект (флаг - 1), или целым числом (флаг - 0), которое называется маленьким целым числом (SMall Integer, SMI) из-за того, что его длина составляет 31 бит. Если для хранения числового значения требуется более 31 бита, V8 упакует число, превратив его в число двойной точности и создаст новый объект для того, чтобы поместить в него это число. Постарайтесь использовать 31-битные числа со знаком везде, где это возможно, для того, чтобы избежать ресурсоёмких операций упаковки чисел в JS-объекты.
Управление памятью, четыре вида утечек памяти и борьба с ними
- Обзор
Некоторые языки, такие как C, обладают низкоуровневыми инструментами для управления памятью, такими, как malloc() и free(). Эти базовые функции используются разработчиками при взаимодействии с операционной системой для явного выделения и освобождения памяти.
В то же время, JavaScript выделяет память, когда нечто (объекты, строки, и так далее) создаётся, и "автоматически", когда созданное больше не используется, освобождает её в ходе процесса, называемого сборкой мусора. Эта вроде бы "автоматическая" природа освобождения ресурсов является источником путаницы и даёт разработчикам, использующим JavaScript (и другие высокоуровневые языки) ложное ощущение того, что они могут совершенно не заботиться об управлении памятью. Это - большая ошибка.
Даже программируя на высокоуровневом языке, разработчики должны понимать принципы, или по крайней мере владеть основами управления памятью. Иногда в системе автоматического управления памятью возникают проблемы (вроде ошибок, ограничений в реализации сборщика мусора и так далее), природу которых разработчики должны понимать для того, чтобы правильно их устранять (или хотя бы находить верные способы их обхода, требующие минимальных дополнительных усилий и не слишком больших объёмов вспомогательного кода).
- Жизненный цикл памяти
Вне зависимости от языка программирования, жизненный цикл памяти практически всегда выглядит одинаково:
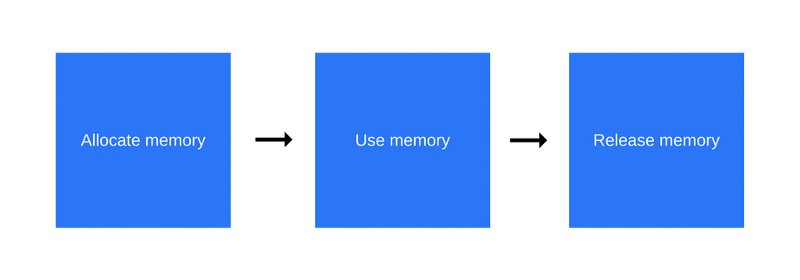
Жизненный цикл памяти: выделение, использование, освобождение.
- Выделение памяти - память выделяется операционной системой, что позволяет программе использовать предоставленные в её распоряжение ресурсы. В низкоуровневых языках (таких, как C), это явная операция, которую необходимо производить разработчику. В высокоуровневых языках, однако, эта задача решается автоматически.
- Использование памяти - это то время, когда программа выполняет какие-либо операции с выделенной ранее памятью. На этом этапе, при обращении к переменным, производятся операции чтения и записи.
- Освобождение памяти - на данном этапе жизненного цикла памяти производится освобождение памяти, которая больше не нужна программе, то есть - возврат её системе. Как и в случае с выделением памяти, освобождение - явная операция в низкоуровневых языках.
- Что такое память?
Прежде чем рассматривать вопросы работы с памятью в JavaScript, поговорим, в двух словах, о том, что такое память.
На аппаратном уровне компьютерная память состоит из множества триггеров. Каждый триггер состоит из нескольких транзисторов, он способен хранить один бит данных. Каждый из триггеров имеет уникальный адрес, поэтому их содержимое можно считывать и перезаписывать. Таким образом, концептуально, мы можем воспринимать компьютерную память как огромный массив битов, которые можно считывать и записывать.
Однако, программисты - люди, а не компьютеры, оперировать отдельными битами им не особенно удобно. Поэтому биты принято организовывать в более крупные структуры, которые можно представлять в виде чисел. 8 бит формируют 1 байт. Помимо байтов здесь в ходу такое понятие, как слова (иногда - длиной 16 битов, иногда - 32).
В памяти хранится много всего:
- Все значения переменных и другие данные, используемые программами.
- Код программ, в том числе - код операционной системы.
Компилятор и операционная система совместно выполняют основной объём работ по управлению памятью без непосредственного участия программиста, однако, мы рекомендуем разработчикам поинтересоваться тем, что происходит в недрах механизмов управления памятью.
Когда код компилируют, компилятор может исследовать примитивные типы данных и заранее вычислить необходимый для работы с ними объём памяти. Требуемый объём памяти затем выделяется программе в пространстве стека вызовов. Пространство, в котором выделяется место под переменные, называется стековым пространством, так как, когда вызываются функции, выделенная им память размещается в верхней части стека. При возврате из функций, они удаляются из стека в порядке LIFO (последним пришёл - первым вышел, Last In First Out). Например, рассмотрим следующие объявления переменных:
int n; // 4 байта int x[4]; // массив из 4-х элементов по 4 байта каждый double m; // 8 байтов
Компилятор, просмотрев данный фрагмент кода (абстрагируемся тут от всего, кроме размеров самих данных), может немедленно выяснить, что для хранения переменных понадобится 4 + 4 × 4 + 8 = 28 байт.
Надо отметить, что приведённые размеры целочисленных переменных и чисел с двойной точностью отражают современное состояние дел. Примерно 20 лет назад целые числа обычно представляли в виде 2-х байтовых конструкций, для чисел двойной точности использовали 4 байта. Код не должен зависеть от байтовых размеров базовых типов данных.
Компилятор сгенерирует код, который будет взаимодействовать с операционной системой, запрашивая необходимое число байтов в стеке для хранения переменных.
В вышеприведённом примере компилятору известны адреса участков памяти, где хранится каждая переменная. На самом деле, если мы используем в коде имя переменной n, оно преобразуется во внутреннее представление, которое выглядит примерно так: "адрес памяти 4127963".
Обратите внимание на то, что если мы попытаемся обратиться к элементу массива из нашего примера, использовав конструкцию x[4], мы, на самом деле, обратимся к данным, которые соответствуют переменной m. Так происходит из-за того, что элемента массива с индексом 4 не существует, запись вида x[4] укажет на область памяти, которая на 4 байта дальше, чем тот участок памяти, который выделен для последнего из элементов массива - x[3]. Попытка обращения к x[4] может закончится чтением (или перезаписью) некоторых битов переменной m. Подобное, практически гарантированно, приведёт к нежелательным последствиям в ходе выполнения программы. Расположение переменных в памяти:
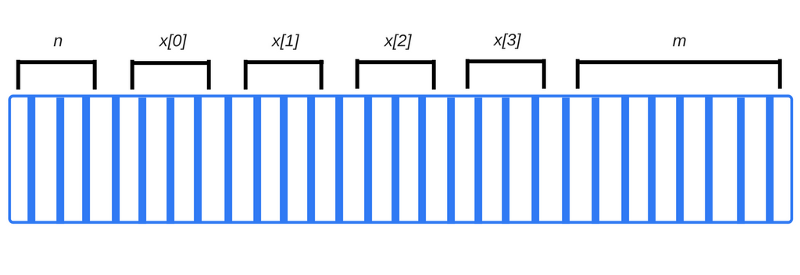
Когда функция вызывает другую функцию, каждой них достаётся собственный участок стека. Здесь хранятся все их локальные переменные и указатель команд, который хранит данные о том, где был выполнен вызов. Когда функция завершает работу, блоки памяти, занятые ей, снова делаются доступными для других целей.
- Динамическое выделение памяти
К сожалению, всё усложняется, когда мы, во время компиляции, не знаем, сколько памяти понадобится для переменной. Представьте себе, что мы хотим сделать примерно следующее:
int n = readInput(); // прочесть данные, введённые пользователем ... // создать массив с n элементами
В подобной ситуации компилятор не знает, сколько памяти понадобится для хранения массива, так как размер массива определяет значение, которое введёт пользователь.
В результате компилятор не сможет зарезервировать память для переменной в стеке. Вместо этого нашей программе придётся явно запросить у операционной системы нужное количество памяти во время её выполнения. Эта память выделяется в так называемой куче.
Разница между статическим и динамическим выделением памяти:
- Статическое выделение памяти:
- Объём должен быть известен во время компиляции.
- Производится во время компиляции программы.
- Память выделяется в стеке.
- Порядок выделения памяти FILO (первым вошёл - последним вышел, First In Last Out).
- Динамическое выделение памяти:
- Объём может быть неизвестен во время компиляции.
- Производится во время выполнения программы.
- Память выделяется в куче.
- Определённого порядка выделения памяти нет.
Для того, чтобы полностью понять, как работает динамическое выделение памяти, нам понадобится подробно обсудить концепцию указателей.
- Выделение памяти в JavaScript
Сейчас мы поговорим о том, как первый шаг жизненного цикла памяти (выделение) реализуется в JavaScript.
JavaScript освобождает разработчика от ответственности за управление выделением памяти. JS делает это самостоятельно, вместе с объявлением переменных.
var n = 374; // выделение памяти для числа
var s = 'sessionstack'; // выделение памяти для строки
var o = {
a: 1,
b: null
}; // выделение памяти для объекта и содержащихся в нём значений
var a = [1, null, 'str']; // выделение памяти для массива и содержащихся в нём значений (похоже на работу с объектом)
function f(a) {
return a + 3;
} // выделение памяти для функции (она является вызываемым объектом)
// объявление функционального выражения также приводит к выделению памяти под объект
someElement.addEventListener('click', function() {
someElement.style.backgroundColor = 'blue';
}, false);
Вызовы некоторых функций также приводят к выделению памяти под объект:
var d = new Date(); // выделение памяти под объект типа Date
var e = document.createElement('div'); // выделение памяти для элемента DOM
Вызовы методов тоже могут приводить к выделению памяти под новые значения или объекты:
var s1 = 'sessionstack'; var s2 = s1.substr(0, 3); // s2 - это новая строка // Так как строки неизменяемы, // JavaScript может решить не выделять память, // а просто сохранить диапазон [0, 3]. var a1 = ['str1', 'str2']; var a2 = ['str3', 'str4']; var a3 = a1.concat(a2); // новый массив с 4 элементами является результатом // конкатенации элементов a1 и a2
- Использование памяти в JavaScript
Использование выделенной памяти в JavaScript, как правило, означает её чтение и запись. Это может быть сделано путём чтения или записи значения переменной или свойства объекта, или даже при передаче аргумента функции.
- Освобождение памяти, которая больше не нужна
Большинство проблем с управлением памятью возникает на этой стадии.
Самой сложной задачей является выяснение того, когда выделенная память больше не нужна программе. Для этого часто требуется, чтобы разработчик определил, где в программе некий фрагмент памяти больше не нужен и освободил бы его.
Высокоуровневые языки имеют встроенную подсистему, которая называется сборщиком мусора. Роль этой подсистемы заключается в отслеживании операций выделения памяти и использование её для того, чтобы узнать, когда фрагмент выделенной памяти больше не нужен. Если это так, сборщик мусора может автоматически освободить этот фрагмент.
К сожалению, этот процесс не отличается абсолютной точностью, так как общая проблема выяснения того, нужен или нет некий фрагмент памяти, неразрешима (не поддаётся алгоритмическому решению).
Большинство сборщиков мусора работают, собирая память, к которой нельзя обратится, то есть такую, все переменные, указывающую на которую, недоступны. Это, однако, слишком смелое предположение о возможности освобождения памяти, так как в любое время некая область памяти может иметь переменные, указывающие на неё в некоей области видимости, хотя с этой областью памяти никогда уже не будут работать в программе.
- Сборка мусора
Основная концепция, на которую полагаются алгоритмы сборки мусора — это концепция ссылок.
В контексте управления памятью, объект ссылается на другой объект, если первый, явно или неявно, имеет доступ к последнему. Например, объект JavaScript имеет ссылку на собственный прототип (явная ссылка) и на значения свойств прототипа (неявная ссылка).
Здесь идея "объекта" расширяется до чего-то большего, нежели обычный JS-объект, сюда включаются, кроме того, функциональные области видимости (или глобальную лексическую область видимости).
Принцип лексической области видимости позволяет задать правила разрешения имён переменных во вложенных функциях. А именно, вложенные функции содержат область видимости родительской функции даже если осуществлён возврат из родительской функции.
- Сборка мусора, основанная на подсчёте ссылок
Это - самый простой алгоритм сборки мусора. Объект считается пригодным для уничтожения, если на него не указывает ни одна ссылка.
Взгляните на следующий код:
var o1 = {
o2: {
x: 1
}
};
// Созданы 2 объекта.
// На объект o2 есть ссылка в объекте o1, как на одно из его свойств.
// На данном этапе ни один объект не может быть уничтожен сборщиком мусора.
var o3 = o1;
// Переменная o3 - это вторая сущность, которая
// имеет ссылку на объект, на который указывает переменная o1.
o1 = 1;
// Теперь на объект, на который изначально ссылалась переменная o1,
// есть лишь одна ссылка, представленная переменной o3
var o4 = o3.o2;
// Ссылка на свойство o2 объекта.
// Теперь на этот объект есть 2 ссылки. Одна - как на свойство другого объекта.
// Вторая - в виде переменной o4
o3 = '374';
// Теперь на объект, на который изначально ссылалась переменная o1, нет ни одной ссылки.
// Он может быть уничтожен сборщиком мусора.
// Однако, на его свойство o2 всё ещё ссылается переменная o4.
// В результате память, занимаемая этим объектом, не может быть освобождена.
o4 = null;
// На свойство o2 объекта, изначально записанного в переменную o1, теперь нет ссылок,
// значит объект может быть уничтожен сборщиком мусора.
- Циклические ссылки - источник проблем
Когда в дело вступают циклические ссылки, проявляются некоторые ограничения вышеописанной модели поиска ненужных объектов. В следующем примере создаются два объекта, ссылающиеся друг на друга. Образуется циклическая ссылка. Объекты окажутся вне досягаемости после вызова функции, то есть они бесполезны, и память, которую они занимают, могла бы быть освобождена. Однако, алгоритм подсчёта ссылок считает, что так как на каждый из двух объектов есть хотя бы одна ссылка, ни один из них нельзя уничтожить.
function f() {
var o1 = {};
var o2 = {};
o1.p = o2; // o1 ссылается на o2
o2.p = o1; // o2 ссылается на o1. Получается циклическая ссылка.
}
f();
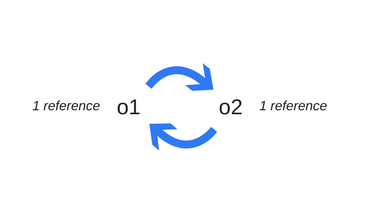
- Алгоритм "пометь и выброси"
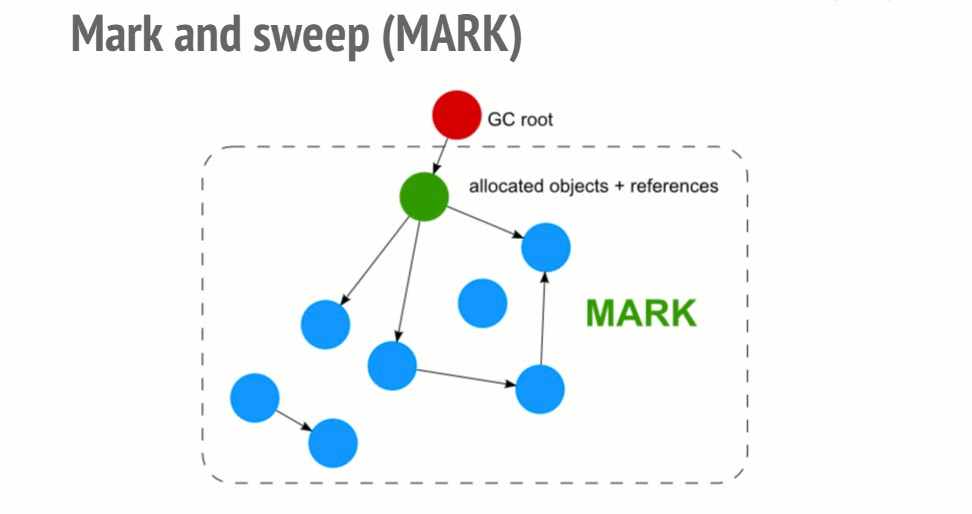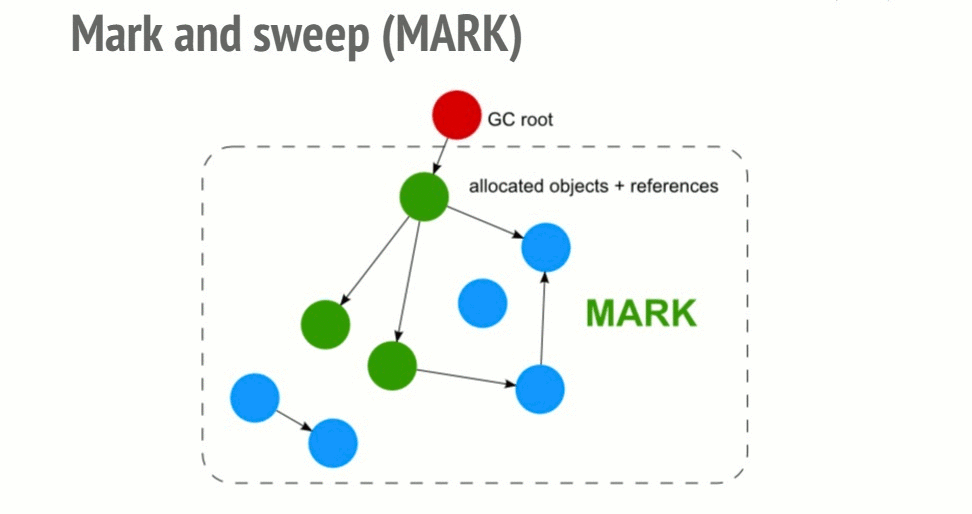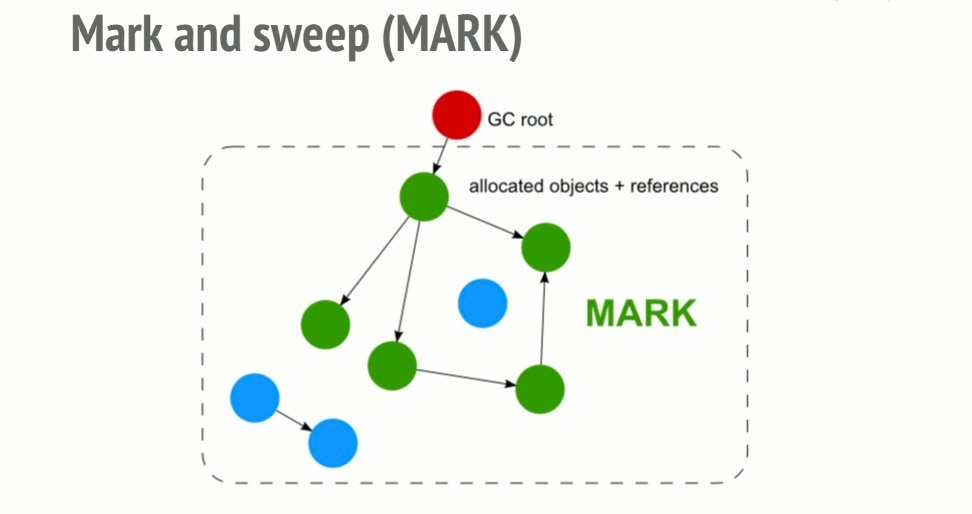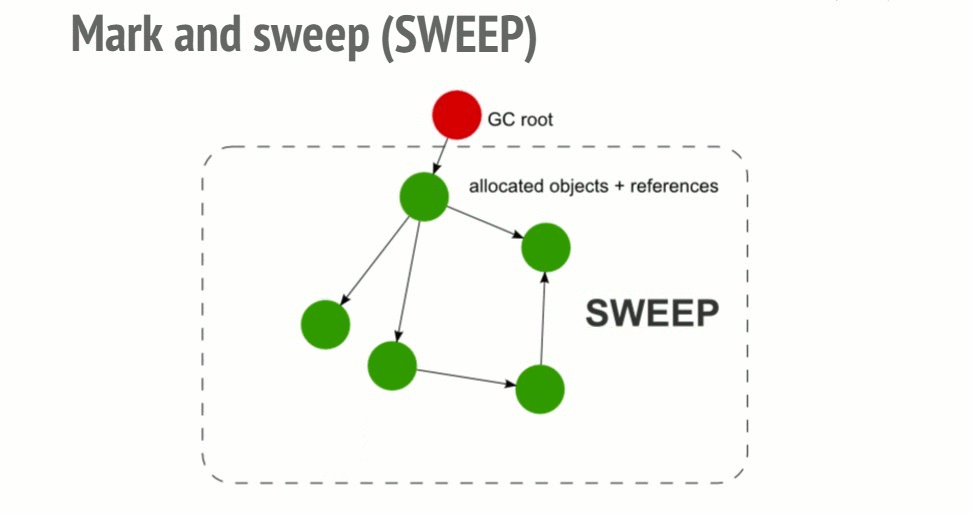
Для того, чтобы принять решение о том, нужно ли сохранить некий объект, алгоритм "пометь и выброси" (mark and sweep) определяет досягаемость объекта.
Алгоритм состоит из следующих шагов:
- Сборщик мусора строит список "корневых объектов". Такие объекты обычно являются глобальными переменными, ссылки на которые имеются в коде. В JavaScript примером глобальной переменной, которая может играть роль корневого объекта, является объект window.
- Все корневые объекты просматриваются и помечаются как активные (то есть, это не "мусор"). Также, рекурсивно, просматриваются все дочерние объекты. Всё, доступ к чему можно получить из корневых объектов, "мусором" не считается.
- Все участки памяти, не помеченные как активные, могут быть признаны подходящими для обработки сборщиком мусора, который теперь может освободить эту память и вернуть её операционной системе.
Этот алгоритм лучше предыдущего, так как ситуация "на объект нет ссылок" ведёт к тому, что объект оказывается недостижимым. Обратное утверждение, как было продемонстрировано в разделе о циклических ссылках, не верно.
С 2012-го года все современные браузеры оснащают сборщиками мусора, в основу которых положен алгоритм "пометь и выброси". За последние годы все усовершенствования, сделанные в сфере сборки мусора в JavaScript (это - генеалогическая, инкрементальная, конкурентная, параллельная сборка мусора), являются усовершенствованиями данного алгоритма, не меняя его основных принципов, которые заключаются в определении достижимости объекта.
- Решение проблемы циклических ссылок
В первом из приведённых выше примеров, после возврата из вызванной функции на два объекта больше не ссылается что-то, к чему можно обратиться из области видимости глобального объекта. Следовательно, сборщик мусора сочтёт их недостижимыми.
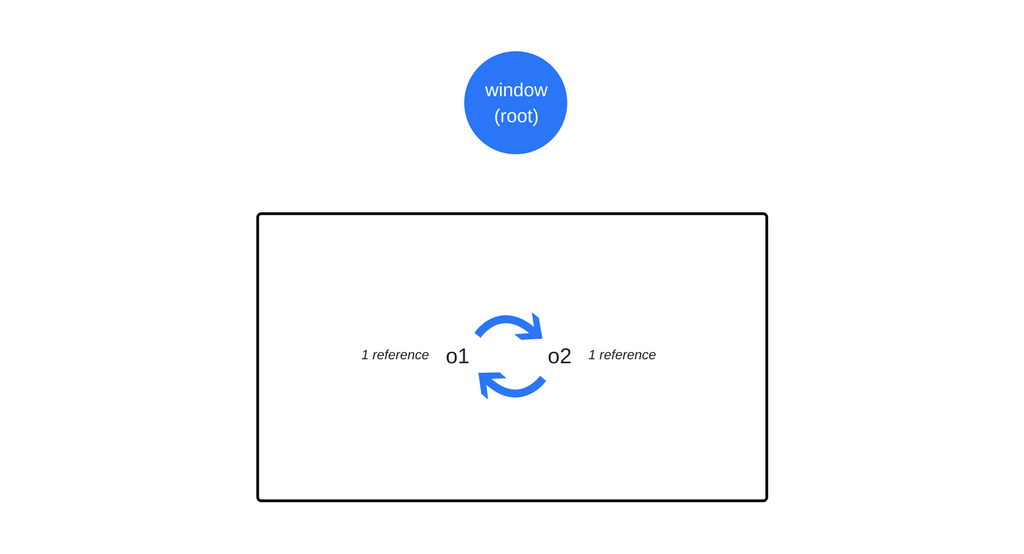
Несмотря на то, что объекты ссылаются друг на друга, к ним нельзя получить доступ из корневого объекта.
- Парадоксальное поведение сборщиков мусора
Хотя сборщики мусора удобны, при их использовании приходится идти на определённые компромиссы. Один из них - недетерминированность. Другими словами, сборщики мусора непредсказуемы. Нельзя точно сказать, когда будет выполнена сборка мусора. Это означает, что в некоторых случаях программы используют больше памяти, чем им на самом деле нужно.
В других случаях короткие паузы, вызванные сборкой мусора, могут оказаться заметными в требовательных к производительности приложениях. Хотя непредсказуемость означает, что нельзя точно знать, когда будет произведена сборка мусора, большинство сборщиков мусора используют один и тот же шаблон выполнения операций освобождения памяти. А именно, делают они это при выделении памяти. Если память не выделяется, большинство сборщиков мусора не предпринимают активных действий. Рассмотрим следующий сценарий:
- Было произведено несколько операций, в результате которых выделен значительный объём памяти.
- Большинство элементов, для которых выделялась память (или все они) были помечены как недостижимые. Скажем, это может быть что-то вроде записи null в переменную, которая ранее ссылалась на кэш, который больше не нужен.
- Больше память не выделялась.
При таком сценарии большинство сборщиков мусора не будет выполнять операции по освобождению памяти. Другими словами, даже хотя участки памяти могут быть освобождены, сборщик мусора их освобождать не будет. Такую ситуацию ещё нельзя назвать утечкой памяти, но она приводит к тому, что программа использует больше памяти, чем ей нужно для обычной работы.
- Что такое утечки памяти?
В двух словах, утечки памяти можно определить как фрагменты памяти, которые больше не нужны приложению, но по какой-то причине не возвращённые операционной системе или в пул свободной памяти.

Языки программирования используют разные способы управления памятью. Однако, проблема точного определения того, используется ли на самом деле некий участок памяти или нет, как уже было сказано, неразрешима. Другими словами, только разработчик знает, можно или нет вернуть операционной системе некую область памяти.
Определённые языки программирования предоставляют разработчику вспомогательные средства для управления памятью. Другие языки ожидают от программиста явных указаний касательно используемых и неиспользуемых участков памяти. Подробнее об этом можно почитать в материалах о ручном и автоматическом управлении памятью.
Рассмотрим четыре распространённых типа утечек памяти в JavaScript.
- Утечки памяти в JavaScript и борьба с ними
- Глобальные переменные
В JavaScript используется интересный подход к работе с необъявленными переменными. Обращение к такой переменной создаёт новую переменную в глобальном объекте. В случае с браузерами, глобальным объектом является window. Рассмотрим такую конструкцию:
function foo(arg) {
bar = "some text";
}
Она эквивалентна следующему коду:
function foo(arg) {
window.bar = "some text";
}
Если переменную bar планируется использовать только внутри области видимости функции foo, и при её объявлении забыли о ключевом слове var, будет случайно создана глобальная переменная.
В этом примере утечка памяти, выделенной под простую строку, большого вреда не принесёт, но всё может быть гораздо хуже.
Другая ситуация, в которой может появиться случайно созданная глобальная переменная, может возникнуть при неправильной работе с ключевым словом this:
function foo() {
this.var1 = "potential accidental global";
}
// Функция вызывается сама по себе, при этом this указывает на глобальный объект (window),
// this не равно undefined, или, как при вызове конструктора, не указывает на новый объект
foo();
Для того, чтобы избежать подобных ошибок, можно добавить оператор "use strict"; в начало JS-файла. Это включит так называемый строгий режим, в котором запрещено создание глобальных переменных вышеописанными способами.
Даже если говорить о вполне безобидных глобальных переменных, созданных осознанно, во многих программах их слишком много. Они, по определению, не подвергаются сборке мусора (если только в такую переменную не записать null или какое-то другое значение). В частности, стоит обратить пристальное внимание на глобальные переменные, которые используются для временного хранения и обработки больших объёмов данных. Если вы вынуждены использовать глобальную переменную для хранения большого объёма данных, не забудьте записать в неё null или что-то другое, нужное для дальнейшей работы, после того, как она сыграет свою роль в обработке большого объёма данных.
- Таймеры или забытые коллбэки
В JS-программах использование функции setInterval - обычное явление.
Большинство библиотек, которые дают возможность работать с обозревателями и другими механизмами, принимающими коллбэки, заботятся о том, чтобы сделать недоступными ссылки на эти коллбэки после того, как экземпляры объектов, которым они переданы, становятся недоступными. Однако, в случае с setInterval весьма распространён следующий шаблон:
var serverData = loadData();
setInterval(function() {
var renderer = document.getElementById('renderer');
if(renderer) {
renderer.innerHTML = JSON.stringify(serverData);
}
}, 5000); //Это будет вызываться примерно каждые 5 секунд.
В этом примере показано, что может происходить с таймерами, которые создают ссылки на узлы DOM или на данные, которые в определённый момент больше не нужны.
Объект, представленный переменной renderer, может быть, в будущем, удалён, что сделает весь блок кода внутри обработчика события срабатывания таймера ненужным. Однако, обработчик нельзя уничтожить, освободив занимаемую им память, так как таймер всё ещё активен. Таймер, для очистки памяти, надо остановить. Если сам таймер не может быть подвергнут операции сборки мусора, это будет касаться и зависимых от него объектов. Это означает, что память, занятую переменной serverData, которая, надо полагать, хранит немалый объём данных, так же нельзя очистить.
В случае с обозревателями, важно использовать явные команды для их удаления после того, как они больше не нужны (или после того, как окажутся недоступными связанные объекты).
Раньше это было особенно важно, так как определённые браузеры (старый добрый IE6, например) были неспособны нормально обрабатывать циклические ссылки. В наши дни большинство браузеров уничтожают обработчики обозревателей после того, как объекты обозревателей оказываются недоступными, даже если прослушиватели событий не были явным образом удалены. Однако, рекомендуется явно удалять эти обозреватели до уничтожения объекта. Например:
var element = document.getElementById('launch-button');
var counter = 0;
function onClick(event) {
counter++;
element.innerHtml = 'text ' + counter;
}
element.addEventListener('click', onClick);
// Сделать что-нибудь
element.removeEventListener('click', onClick);
element.parentNode.removeChild(element);
// Теперь, когда элемент выходит за пределы области видимости,
// память, занятая обоими элементами и обработчиком onClick будет освобождена даже в старых браузерах,
// которые не способны нормально обрабатывать ситуации с циклическими ссылками.
В наши дни браузеры (в том числе Internet Explorer и Microsoft Edge) используют современные алгоритмы сборки мусора, которые выявляют циклические ссылки и работают с соответствующими объектами правильно. Другими словами, сейчас нет острой необходимости в использовании метода removeEventListener перед тем, как узел будет сделан недоступным.
Фреймворки и библиотеки, такие, как jQuery, удаляют прослушиватели перед уничтожением узлов (при использовании для выполнения этой операции собственных API). Всё это поддерживается внутренними механизмами библиотек, которые, кроме того, контролируют отсутствие утечек памяти даже если код работает в не самых благополучных браузерах, таких как уже упомянутый выше IE 6.
- Замыкания
Одна из важных и широко используемых возможностей JavaScript - замыкания. Это - внутренняя функция, у которой есть доступ к переменным, объявленным во внешней по отношению к ней функции. Особенности реализации среды выполнения JavaScript делают возможной утечку памяти в следующем сценарии:
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
// ссылка на originalThing
if (originalThing) {
console.log("hi");
}
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log("message");
}
};
};
setInterval(replaceThing, 1000);
Самое важное в этом фрагменте кода то, что каждый раз при вызове replaceThing, в theThing записывается ссылка на новый объект, который содержит большой массив и новое замыкание (someMethod). В то же время, переменная unused хранит замыкание, которое имеет ссылку на originalThing (она ссылается на то, на что ссылалась переменная theThing из предыдущего вызова replaceThing). Во всём этом уже можно запутаться, не так ли? Самое важное тут то, что когда создаётся область видимости для замыканий, которые находятся в одной и той же родительской области видимости, эта область видимости используется ими совместно.
В данном случае в области видимости, созданной для замыкания someMethod, имеется также и переменная unused. Эта переменная ссылается на originalThing. Несмотря на то, что unused не используется, someMethod может быть вызван через theThing за пределами области видимости replaceThing (то есть - из глобальной области видимости). И, так как someMethod и unused находятся в одной и той же области видимости, ссылка на originalThing, записанная в unused, приводит к тому, что эта переменная оказывается активной (это - общая для двух замыканий область видимости). Это не даёт нормально работать сборщику мусора.
Если вышеприведённый фрагмент кода некоторое время поработает, можно заметить постоянное увеличение потребления им памяти. При запуске сборщика мусора память не освобождается. В целом оказывается, что создаётся связанный список замыканий (корень которого представлен переменной theThing), и каждая из областей видимости этих замыканий имеет непрямую ссылку на большой массив, что приводит к значительной утечке памяти.
- Ссылки на объекты DOM за пределами дерева DOM
Иногда может оказаться полезным хранить ссылки на узлы DOM в неких структурах данных. Например, предположим, что нужно быстро обновить содержимое нескольких строк в таблице. В подобной ситуации имеет смысл сохранить ссылки на эти строки в словаре или в массиве. В подобных ситуациях система хранит две ссылки на элемент DOM: одну из них в дереве DOM, вторую - в словаре. Если настанет время, когда разработчик решит удалить эти строки, нужно позаботиться об обеих ссылках.
var elements = {
button: document.getElementById('button'),
image: document.getElementById('image')
};
function doStuff() {
image.src = 'http://example.com/image_name.png';
}
function removeImage() {
// Изображение является прямым потомком элемента body.
document.body.removeChild(document.getElementById('image'));
// В данный момент у нас есть ссылка на #button в
// глобальном объекте elements. Другими словами, элемент button
// всё ещё хранится в памяти, она не может быть очищена сборщиком мусора.
}
Есть ещё одно соображение, которое нужно принимать во внимание при создании ссылок на внутренние элементы дерева DOM или на его концевые вершины.
Предположим, мы храним ссылку на конкретную ячейку таблицы (тег <td>) в JS-коде. Через некоторое время решено убрать таблицу из DOM, но сохранить ссылку на эту ячейку. Чисто интуитивно можно предположить, что сборщик мусора освободит всю память, выделенную под таблицу, за исключением памяти, выделенной под ячейку, на которую у нас есть ссылка. В реальности же всё не так. Ячейка является узлом-потомком таблицы. Потомки хранят ссылки на родительские объекты. Таким образом, наличие ссылки на ячейку таблицы в коде приводит к тому, что в памяти остаётся вся таблица. Учитывайте эту особенность, храня ссылки на элементы DOM в программах.
Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
- Ограничения однопоточной модели выполнения кода
Мы размышляли над следующим вопросом: "Что происходит, когда в стеке вызовов имеется функция, на выполнение которой нужно очень много времени?". Продолжим эти размышления.
Представьте себе сложный алгоритм обработки изображений, реализация которого запускается в браузере. Когда в стеке вызовов есть работающая функция, браузер не может делать больше ничего. Он заблокирован. Это означает, что браузер не может выводить что-либо на экран, не может выполнять другой код. Самое заметное последствие такой ситуации - "тормоза" пользовательского интерфейса. Веб-страницу попросту "заклинивает".
В некоторых случаях это может оказаться не такой уж и серьёзной проблемой. Однако, это - не самое страшное. Как только браузер начинает выполнять слишком много задач, он может достаточно продолжительное время не реагировать на воздействия пользователя. Обычно в подобной ситуации браузеры предпринимают защитные меры и выдают сообщение об ошибке, спрашивая у пользователя, следует ли закрыть проблемную страницу. Лучше бы пользователю не видеть таких сообщений. Они полностью разрушают все усилия разработчиков по созданию красивых и удобных интерфейсов.
Как же быть, если хочется, чтобы веб-приложение и выглядело хорошо, и могло выполнять сложные вычисления? Начнём поиск ответа на этот вопрос с анализа строительных блоков JS-приложений.
- Строительные блоки программ на JavaScript
Код JavaScript-приложения можно разместить в одном .js-файле, но оно, почти наверняка, будет состоять из нескольких блоков. При этом лишь один из этих блоков будет выполняться в некий определённый момент времени, скажем - прямо сейчас. Остальные будут выполняться позже. Наиболее распространённые блоки кода в JavaScript - это функции.
Взглянем на следующий пример:
// ajax(..) - некая библиотечная Ajax-функция
var response = ajax('https://example.com/api');
console.log(response);
// в переменной response не будет ответа от api
Возможно, вы знаете о том, что стандартные Ajax-запросы не выполняются синхронно. Это означает, что функция ajax(..), сразу после её вызова, не может возвратить некое значение, которое могло бы быть присвоено переменной response.
Простой механизм организации "ожидания" результата, возвращаемого асинхронной функцией, заключается в использовании так называемых функций обратного вызова, или коллбэков:
ajax('https://example.com/api', function(response) {
console.log(response); // теперь переменная response содержит ответ api
});
Тут хотелось бы отметить, что выполнить Ajax-запрос можно и синхронно. Однако, так делать не следует. Если выполнить синхронный Ajax-запрос, пользовательский интерфейс JS-приложения окажется заблокированным. Пользователь не сможет щёлкнуть по кнопке, ввести данные в поле, он не сможет даже прокрутить страницу. Синхронное выполнение Ajax-запросов не даст пользователю взаимодействовать с приложением. Такой подход хотя и возможен, приводит к катастрофическим последствиям.
Вот как этот ужас выглядит, однако, пожалуйста, никогда не пишите ничего подобного, не превращайте веб в место, где невозможно нормально работать:
// Исходим из предположения, что вы пользуетесь jQuery
jQuery.ajax({
url: 'https://api.example.com/endpoint',
success: function(response) {
// Это - коллбэк.
},
async: false // А вот это - то, чего делать настоятельно не рекомендуется
});
Здесь мы приводили примеры на Ajax-запросах, однако, любой фрагмент кода можно запустить в асинхронном режиме.
Например, сделать это можно с помощью функции setTimeout(callback, milliseconds). Она позволяет планировать выполнение событий (задавая тайм-аут), которые должны произойти позже момента обращения к этой функции. Рассмотрим пример:
function first() {
console.log('first');
}
function second() {
console.log('second');
}
function third() {
console.log('third');
}
first();
setTimeout(second, 1000); // вызвать функцию second через 1000 миллисекунд
third();
Вот что этот код выведет в консоль:
first third second
- Изучение цикла событий
Это может показаться странным, но до ES6 JavaScript, несмотря на то, что он позволял выполнять асинхронные вызовы (вроде вышеописанного setTimeout), не содержал встроенных механизмов асинхронного программирования. JS-движки занимались только однопоточным выполнением неких фрагментов кода, по одному за раз.
Итак, кто сообщает JS-движку о том, что он должен исполнить некий фрагмент программы? В реальности движок не работает в изоляции - его собственный код выполняется внутри некоего окружения, которым, для большинства разработчиков, является либо браузер, либо Node.js. На самом деле, в наши дни существуют JS-движки для самых разных видов устройств — от роботов до умных лампочек. Каждое подобное устройство представляет собственный вариант окружения для JS-движка.
Общей характеристикой всех подобных сред является встроенный механизм, который называется циклом событий (event loop). Он поддерживает выполнение фрагментов программы, вызывая для этого JS-движок.
Это означает, что движок можно считать средой выполнения любого JS-кода, вызываемой по требованию. А планированием событий (то есть - сеансов выполнения JS-кода) занимаются механизмы окружения, внешние по отношению к движку.
Итак, например, когда ваша программа выполняет Ajax-запрос для загрузки каких-то данных с сервера, вы пишете команду для записи этих данных в переменную response внутри коллбэка, и JS-движок сообщает окружению: "Послушай, я собираюсь приостановить выполнение программы, но когда ты закончишь выполнять этот сетевой запрос и получишь какие-то данные, пожалуйста, вызови этот коллбэк".
Затем браузер устанавливает прослушиватель, ожидающий ответ от сетевой службы, и когда у него есть что-то, что можно возвратить в программу, выполнившую запрос, он планирует вызов коллбэка, добавляя его в цикл событий.
Взгляните на следующую схему:
Что представляют собой Web API? В целом, это - потоки, к которым у нас нет прямого доступа, мы можем лишь выполнять обращения к ним. Они встроены в браузер, где и выполняются асинхронные действия. Если вы разрабатываете под Node.js, то подобные API реализованы средствами С++.
Итак, что же такое цикл событий?
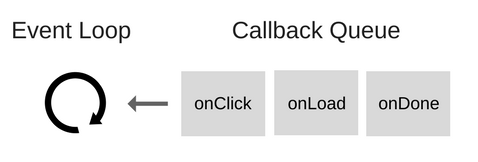
Цикл событий решает одну основную задачу: наблюдает за стеком вызовов и очередью коллбэков (callback queue). Если стек вызовов пуст, цикл берёт первое событие из очереди и помещает его в стек, что приводит к запуску этого события на выполнение. Подобная итерация называется тиком (tick) цикла событий. Каждое событие - это просто коллбэк.
Рассмотрим следующий пример:
console.log('Hi');
setTimeout(function cb1() {
console.log('cb1');
}, 5000);
console.log('Bye');
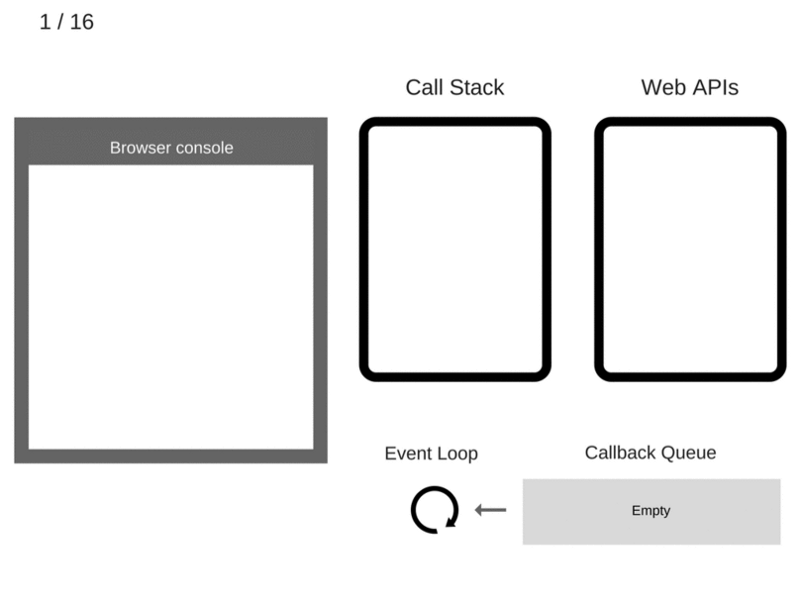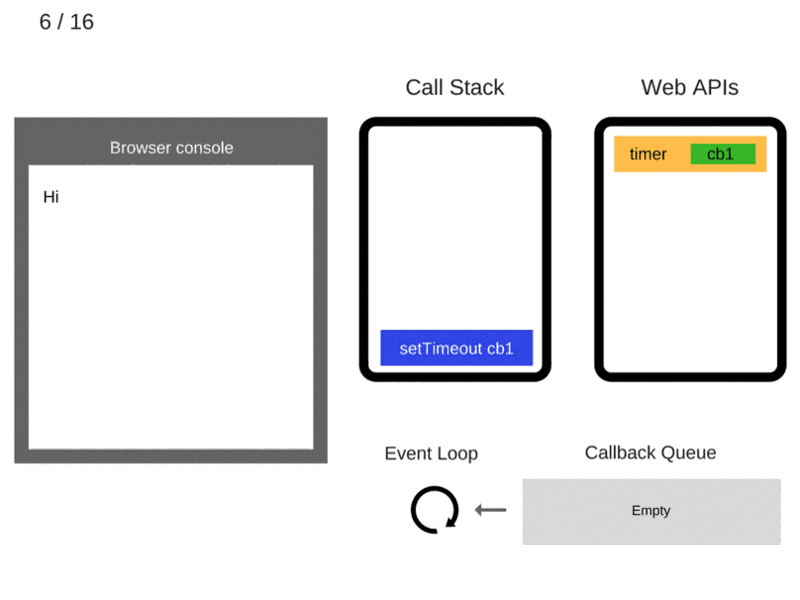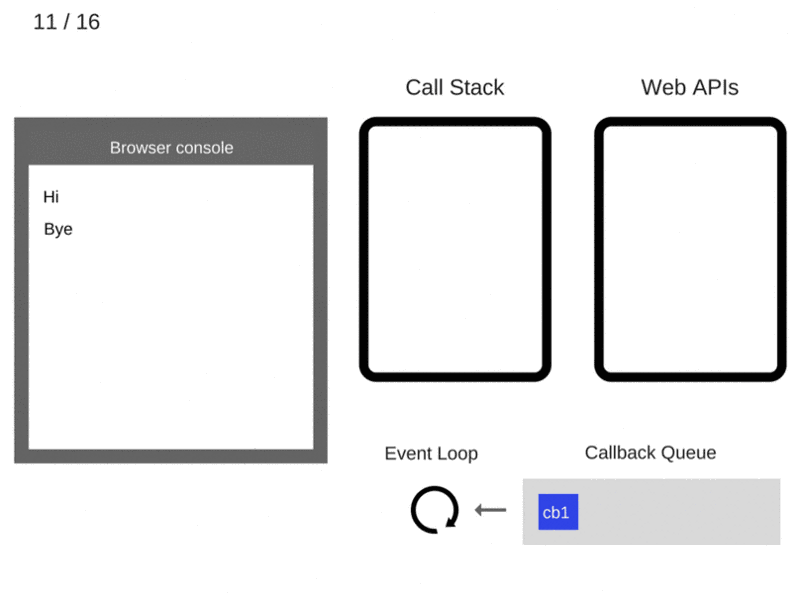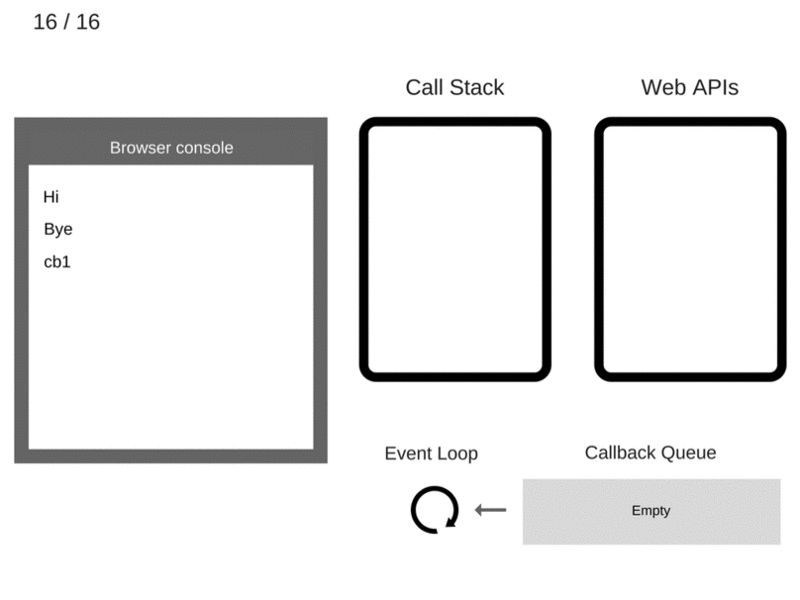
Займёмся пошаговым "выполнением" этого кода и посмотрим, что при этом происходит в системе.
1. Пока ничего не происходит. Консоль браузера чиста, стек вызовов пуст.
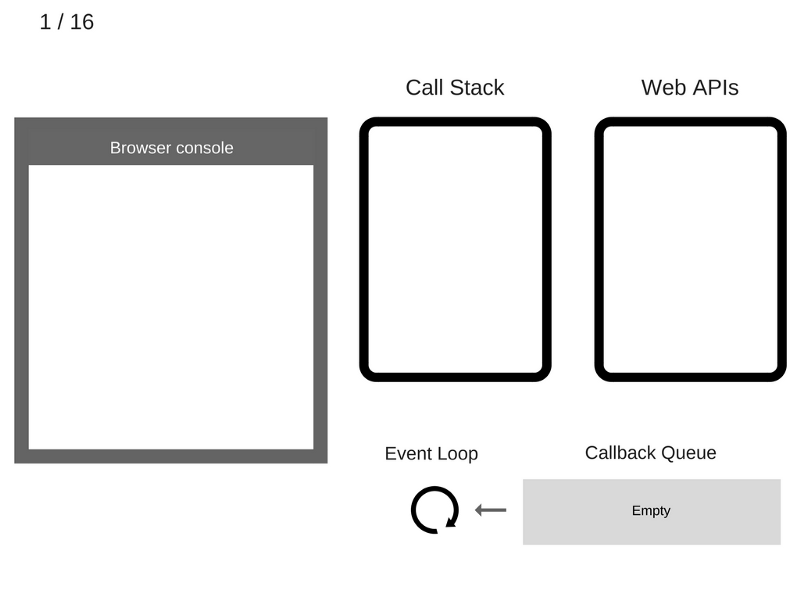
2. Команда console.log('Hi') добавляется в стек вызовов.
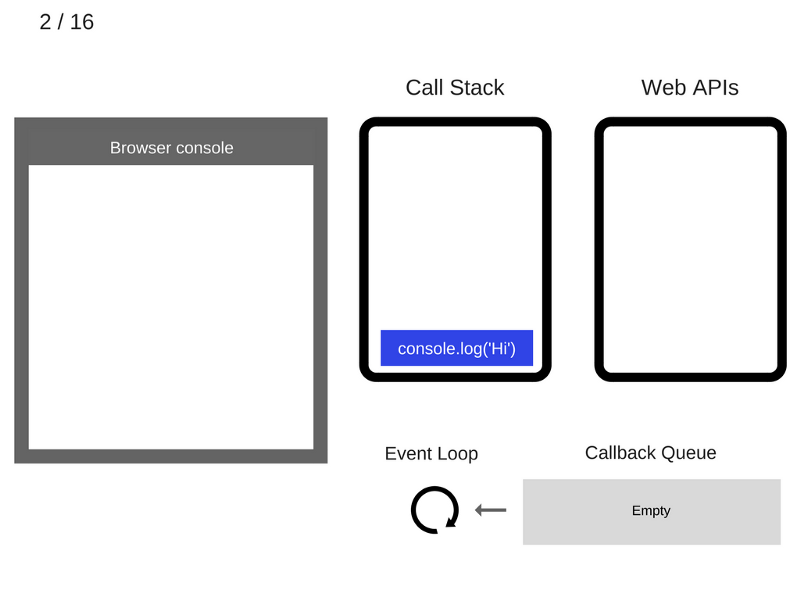
3. Команда console.log('Hi') выполняется.
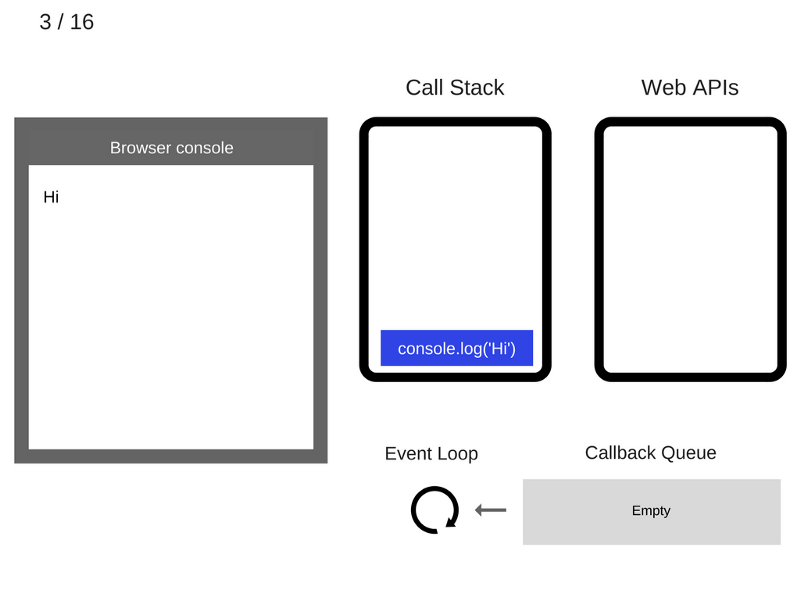
4. Команда console.log('Hi') удаляется из стека вызовов.
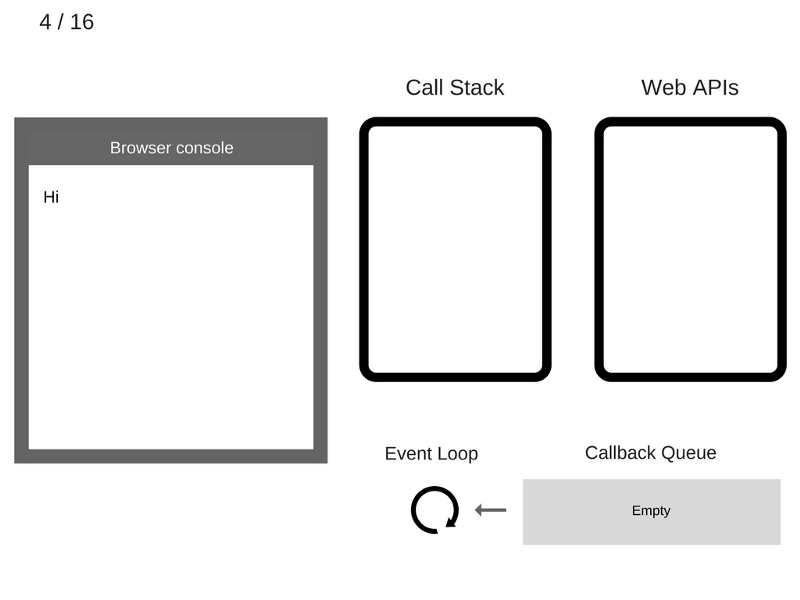
5. Команда setTimeout(function cb1() { ... }) добавляется в стек вызовов.
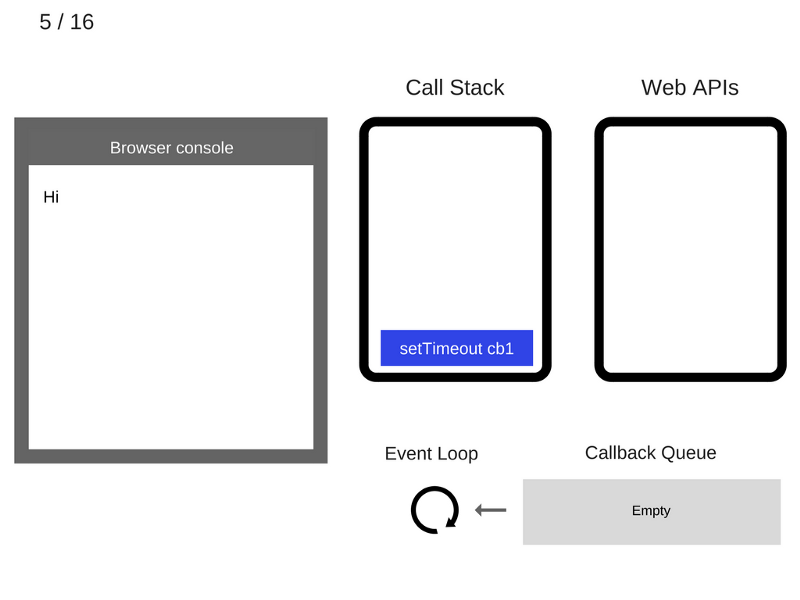
6. Команда setTimeout(function cb1() { ... }) выполняется. Браузер создаёт таймер, являющийся частью Web API. Он будет выполнять обратный отсчёт времени.
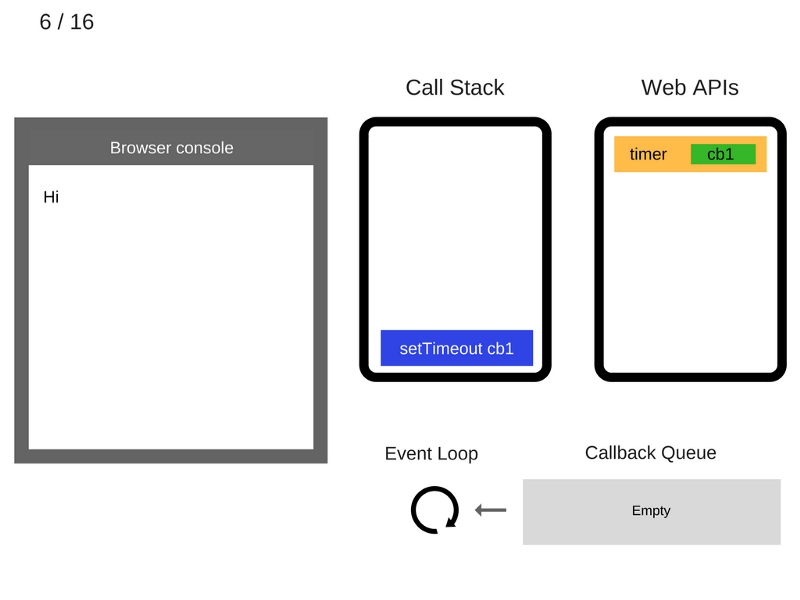
7. Команда setTimeout(function cb1() { ... }) завершила работу и удаляется из стека вызовов.
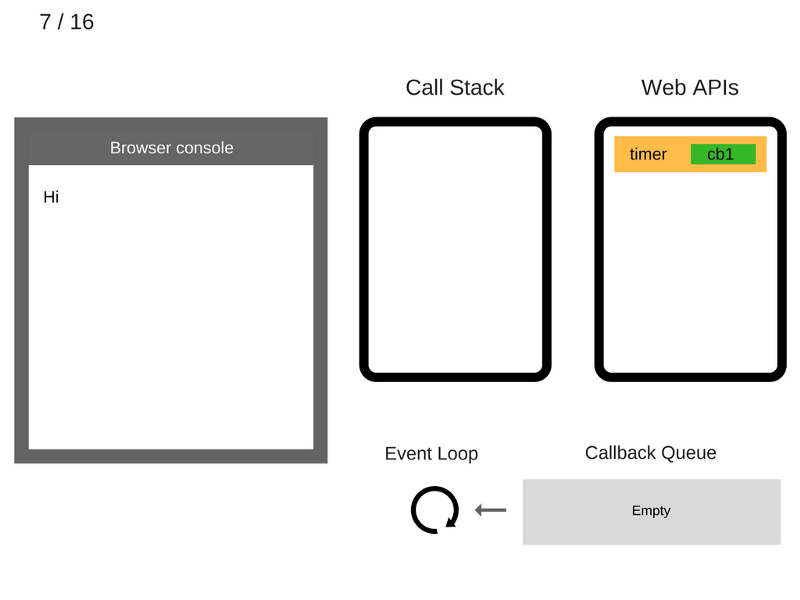
8. Команда console.log('Bye') добавляется в стек вызовов.
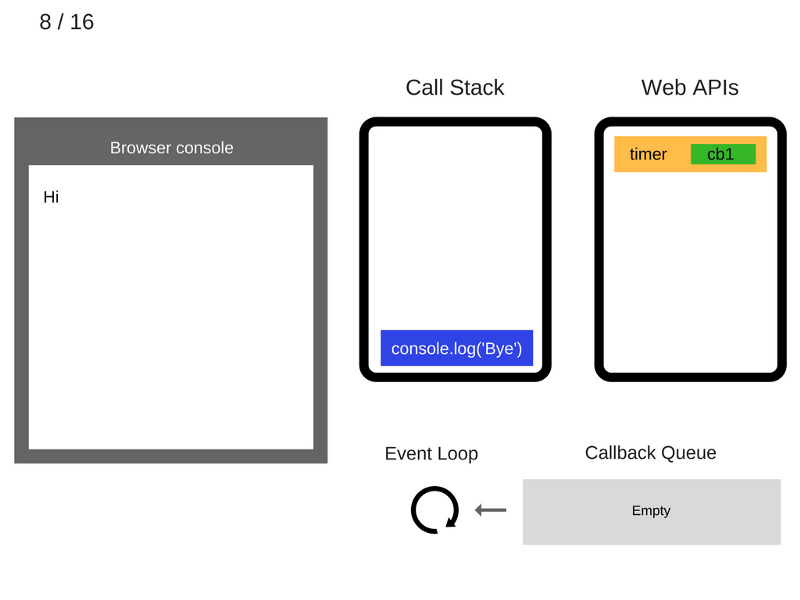
9. Команда console.log('Bye') выполняется.
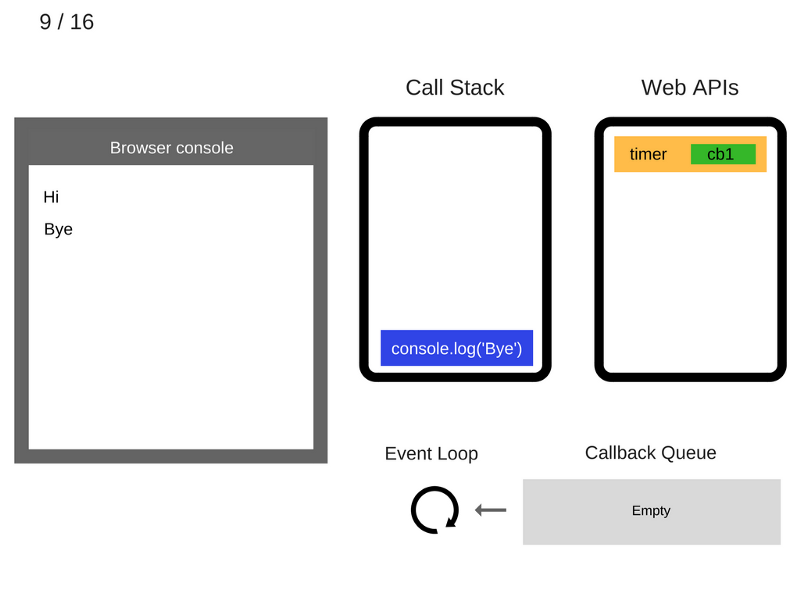
10. Команда console.log('Bye') удаляется из стека вызовов.
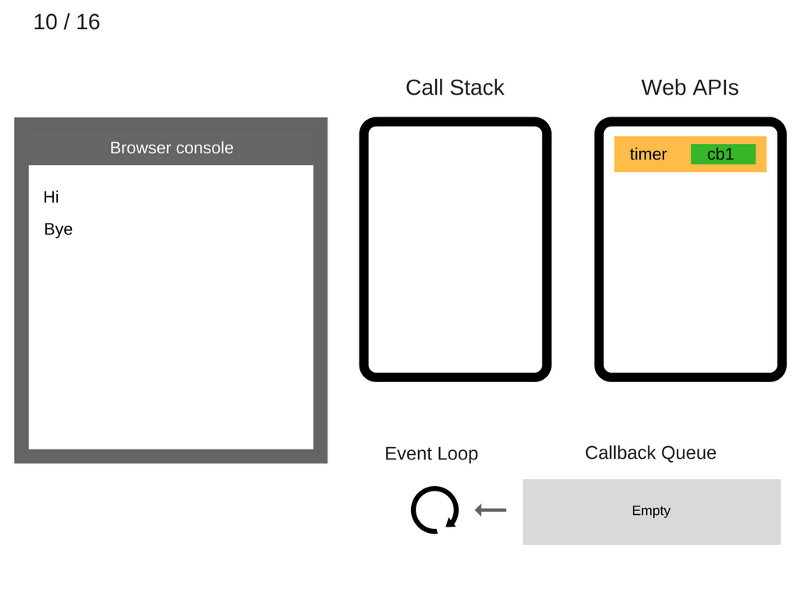
11. После того, как пройдут, как минимум, 5000 мс., таймер завершает работу и помещает коллбэк cb1 в очередь коллбэков.
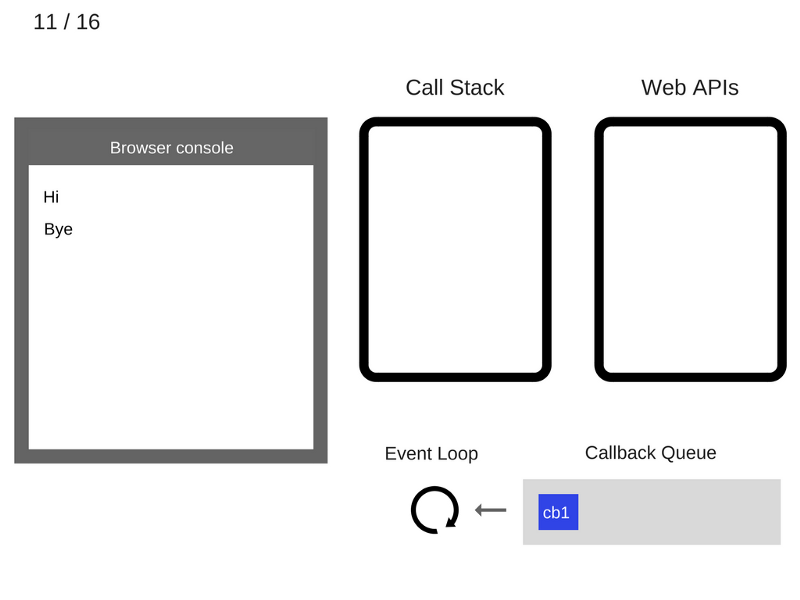
12. Цикл событий берёт функцию cb1 из очереди коллбэков и помещает её в стек вызовов.
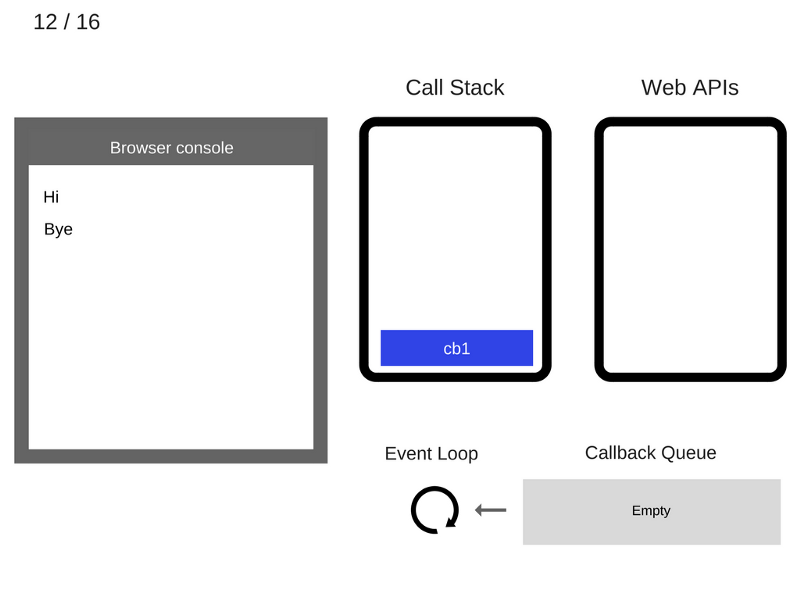
13. Функция cb1 выполняется и добавляет console.log('cb1') в стек вызовов.
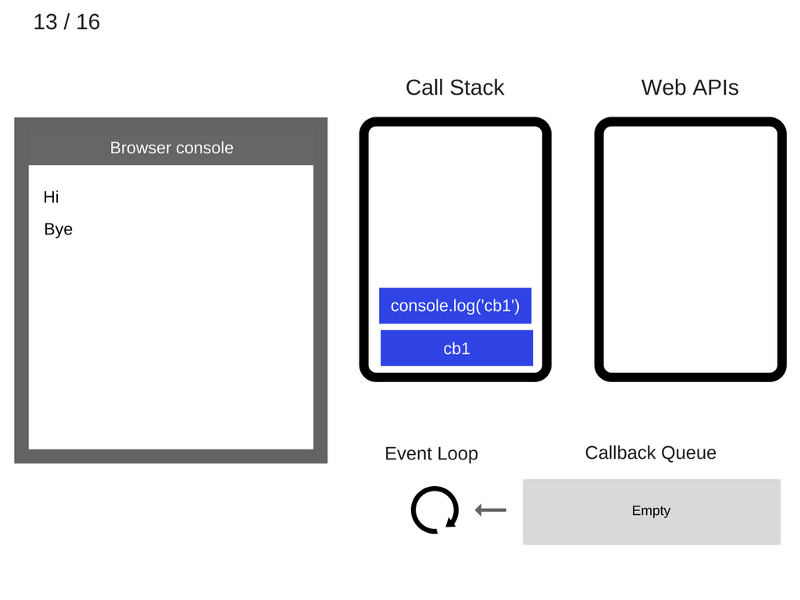
14. Команда console.log('cb1') выполняется.
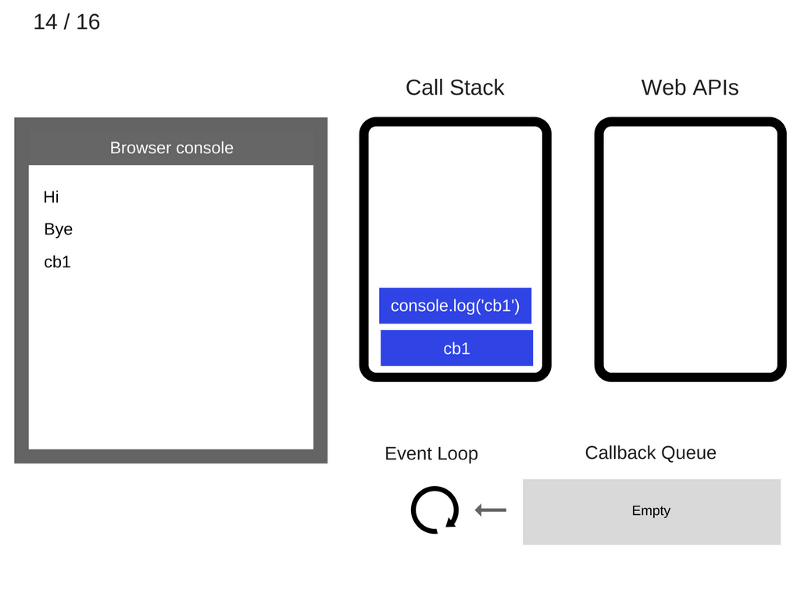
15. Команда console.log('cb1') удаляется из стека вызовов.
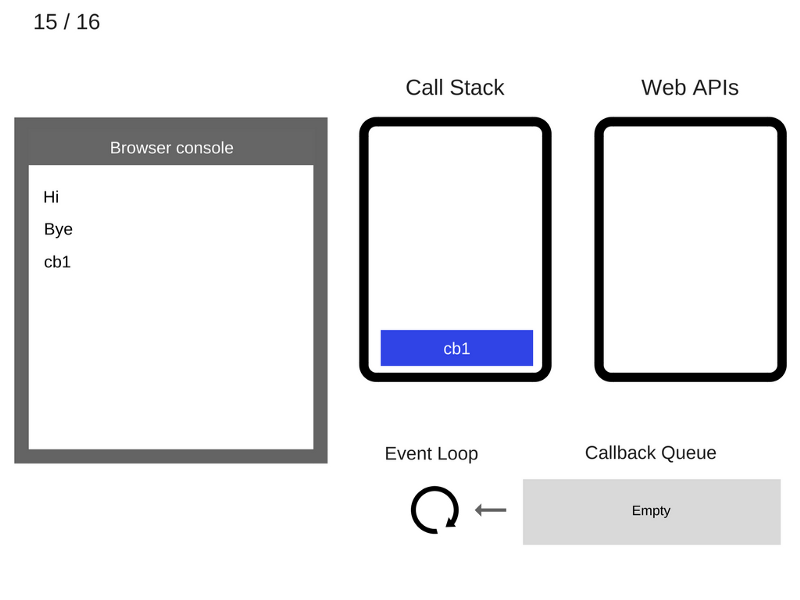
16. Функция cb1 удаляется из стека вызовов.
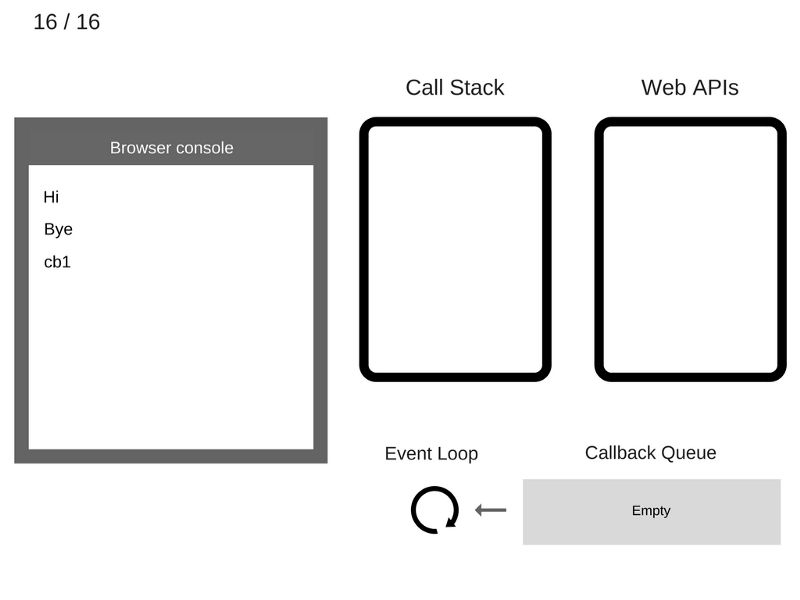
Вот, для закрепления, то же самое в анимированном виде.
Интересно заметить, что спецификация ES6 определяет то, как должен работать цикл событий, а именно, указывает на то, что технически он находится в пределах ответственности JS-движка, который начинает играть более важную роль в экосистеме JS. Основная причина подобного заключается в том, что в ES6 появились промисы и им требуется надёжный механизм планирования операций в очереди цикла событий.
- Как работает setTimeout(...)
Вызов setTimeout(...) не приводит к автоматическому размещению коллбэка в очереди цикла событий. Эта команда запускает таймер. Когда таймер срабатывает, окружение помещает коллбэк в цикл событий, в результате, в ходе какого-то из будущих тиков, этот коллбэк будет взят в работу и выполнен. Взгляните на этот фрагмент кода:
setTimeout(myCallback, 1000);
Выполнение этой команды не означает, что myCallback будет выполнен через 1000 мс., правильнее будет сказать, что через 1000 мс. myCallback будет добавлен в очередь. В очереди, однако, могут быть другие события, добавленные туда ранее, в результате нашему коллбэку придётся подождать.
Существует довольно много статей, предназначенных для тех, кто только начинает заниматься асинхронным программированием на JavaScript. В них можно найти рекомендацию по использованию команды setTimeout(callback, 0). Теперь вы знаете, как работает цикл событий и что происходит при вызове setTimeout. Учитывая это, вполне очевидно то, что вызов setTimeout со вторым аргументом, равным 0, просто откладывает вызов коллбэка до момента очищения стека вызовов.
Взгляните на следующий пример:
console.log('Hi');
setTimeout(function() {
console.log('callback');
}, 0);
console.log('Bye');
Хотя время, на которое установлен таймер, составляет 0 мс., в консоль будет выведено следующее:
Hi Bye callback
- Задания ES6
В ES6 появилась новая концепция, которая называется очередью заданий (Job Queue). Эту конструкцию можно считать слоем, расположенным поверх очереди цикла событий. Вполне возможно, вы с ней сталкивались, когда вам приходилось разбираться с особенностями асинхронного поведения промисов.
Сейчас мы опишем это в двух словах, в результате, когда будем говорить об асинхронной разработке с использованием промисов, вы будете понимать, как асинхронные действия планируются и обрабатываются.
Представьте себе это так: очередь заданий - это очередь, которая присоединена к концу каждого тика в очереди цикла событий. Некие асинхронные действия, которые могут произойти в течение тика цикла событий не приведут к тому, что новое событие будет добавлено в очередь цикла событий, но вместо этого элемент (то есть - задание) будет добавлен в конец очереди заданий текущего тика. Это означает, что добавляя в очередь команды, которые должны быть выполнены в будущем, вы можете быть уверены в том, в каком порядке они будут выполняться.
Выполнение задания может приводить к добавлению дополнительных заданий в конец той же очереди. В теории возможно, чтобы "циклическое" задание (задание которое занимается добавлением других заданий) работало бесконечно, истощая ресурсы программы, необходимые для перехода к следующему тику цикла событий. Концептуально это было бы похожим на создание бесконечного цикла вроде while(true).
Задания - это что-то вроде "хака" setTimeout(callback, 0), но реализованные так, что они дают возможность соблюдения последовательности операций, которые выполняются позже, но так скоро, насколько это возможно.
- Коллбэки
Как вы уже знаете, коллбэки являются самым распространённым средством выражения и выполнения асинхронных действий в программах на JavaScript. Более того, коллбэк является наиболее фундаментальным асинхронным шаблоном языка. Бесчисленное множество JS-приложений, даже весьма хитроумных и сложных, основано исключительно на коллбэках.
Всё это хорошо, но и коллбэки не идеальны. Поэтому многие разработчики пытаются найти более удачные шаблоны асинхронной разработки. Невозможно, однако, эффективно использовать любую абстракцию, не понимая того, как всё работает, что называется, под капотом.
Ниже мы подробно рассмотрим пару таких абстракций для того, чтобы показать, почему более продвинутые асинхронные шаблоны, о которых мы ещё поговорим, необходимы и даже рекомендованы к использованию.
- Вложенные коллбэки
Взгляните на следующий код:
listen('click', function (e) {
setTimeout(function() {
ajax('https://api.example.com/endpoint', function (text) {
if (text == "hello") {
doSomething();
} else if (text == "world") {
doSomethingElse();
}
});
}, 500);
});
Здесь имеется цепочка из трёх вложенных в друг друга функций, каждая из них представляет собой шаг в последовательности действий, выполняемых асинхронно. Такой код часто называют адом коллбэков. Но "ад" кроется не в том, что функции вложены. Это - гораздо более глубокая проблема.
Разберём этот код. Сначала мы ожидаем события click, затем ждём срабатывания таймера, и, наконец, ожидаем прихода Ajax-ответа, после прихода которого всё это может повториться снова.
На первый взгляд может показаться, что этот код выражает свою асинхронную природу вполне естественно, в виде последовательных шагов. Вот первый шаг:
listen('click', function (e) {
// ..
});
Вот второй:
setTimeout(function() {
// ..
}, 500);
Вот третий:
ajax('https://api.example.com/endpoint', function (text) {
// ..
});
И наконец, происходит вот это:
if (text == "hello") {
doSomething();
} else if (text == "world") {
doSomethingElse();
}
Итак, подобный подход к написанию асинхронного кода выглядит гораздо более естественным, правда? Должен быть способ писать его именно так.
- Промисы
Взгляните на следующий фрагмент кода:
var x = 1; var y = 2; console.log(x + y);
Тут всё очень просто: значения переменных x и y складываются и выводятся в консоль. Но что если значение x или y недоступно и его ещё предстоит задать? Скажем, нам нужно получить с сервера то, что будет записано в x и y, а потом уже использовать эти данные в выражении. Представим, что у нас имеются функции loadX и loadY, которые, соответственно, загружают значения x и y с сервера. Затем представьте, что имеется функция sum, которая складывает значения x и y как только они будут загружены.
Это всё может выглядеть так (страшновато получилось, правда?):
function sum(getX, getY, callback) {
var x, y;
getX(function(result) {
x = result;
if (y !== undefined) {
callback(x + y);
}
});
getY(function(result) {
y = result;
if (x !== undefined) {
callback(x + y);
}
});
}
// Синхронная или асинхронная функция, которая загружает значение 'x'
function fetchX() {
// ..
}
// Синхронная или асинхронная функция, которая загружает значение 'y'
function fetchY() {
// ..
}
sum(fetchX, fetchY, function(result) {
console.log(result);
});
Тут есть одна очень важная вещь. А именно, в этом коде мы относимся к x и y как к значениям, которые будут получены в будущем, и мы описываем операцию sum(...) (при её вызове, не вдаваясь в детали реализации) так, будто для её выполнения не имеет значения, доступны или нет значения x и y на момент её вызова.
Конечно, представленный здесь грубый подход, основанный на коллбэках, оставляет желать лучшего. Это - лишь первый маленький шаг к пониманию преимуществ, которые даёт возможность оперировать "будущими значениями", не беспокоясь о конкретном времени их появления.
- Значение промиса
Сначала взглянем на то, как можно выразить операцию x + y с использованием промисов:
function sum(xPromise, yPromise) {
// `Promise.all([ .. ])` принимает массив промисов,
// и возвращает новый промис, который ожидает
// разрешения всех промисов, которые были в массиве
return Promise.all([xPromise, yPromise])
// когда этот промис будет разрешён, возьмём
// полученные значения 'X' и 'Y' и суммируем их.
.then(function(values) {
// 'values' - это массив сообщений из ранее разрешённых промисов
return values[0] + values[1];
});
}
// 'fetchX()' и 'fetchY()' возвращают промисы для
// соответствующих значений. Эти значения могут быть
// доступны *сейчас* или *позже*.
sum(fetchX(), fetchY())
// получаем промис для сложения этих двух чисел.
// теперь мы используем вызов 'then(...)' для организации ожидания
// разрешения этого возвращённого промиса.
.then(function(sum) {
console.log(sum);
});
В этом примере есть два слоя промисов.
Вызовы fetchX() и fetchY() выполняются напрямую, и значения, которые они возвращают (промисы!) передаются в sum(...). Те значения, которые представляют эти промисы, могут быть готовы к дальнейшему использованию сейчас или позже, но каждый промис ведёт себя так, что сам по себе момент доступности значений неважен. В результате о значениях x и y мы рассуждаем без привязки ко времени. Это - будущие значения.
Второй слой промисов - это промис, который создаёт и возвращает (с помощью Promise.all([ ... ])) вызов sum(...). Мы ожидаем значение, которое возвратит этот промис, вызывая then(...). Когда операция sum(...) завершается, наше будущее значение суммы готово и мы можем вывести его на экран. Мы скрываем логику ожидания будущих значений x и y внутри sum(...).
Обратите внимание на то, что внутри sum(...) вызов Promise.all([ ... ]) создаёт промис (который ожидает разрешения promiseX и promiseY). Вызов .then(...) создаёт ещё один промис, команда которого values[0] + values[1] немедленно выполняется (промис разрешается, давая результат сложения). Таким образом, вызов then(...), который мы, в конце примера, присоединили к вызову sum(...), на самом деле работает со вторым возвращённым промисом, а не с тем, который создан командой Promise.all([ ... ]). Кроме того, хотя мы не присоединяем других вызовов ко второму then(...), он тоже создаёт ещё один промис, с которым, если надо, вполне можно продолжить работу. Как результат, мы получаем возможность объединения вызовов .then(...) в цепочки.
При использовании промисов вызов then(...) может, на самом деле, принимать две функции. Первая функция - для случая, когда промис успешно разрешается. Вторая - для ситуации, когда промис оказывается отклонённым:
sum(fetchX(), fetchY())
.then(
// обработчик успешного разрешения промиса
function(sum) {
console.log( sum );
},
// обработчик отклонения промиса
function(err) {
console.error( err ); // что-то пошло не так
}
);
Если при загрузке значений x или y что-то пошло не так, или произошёл сбой в ходе сложения этих значений, промис, возвращённый функцией sum(...), будет отклонён. После этого будет вызван второй коллбэк, переданный then(...), представляющий собой обработчик ошибки. Он получит сообщение об ошибке от промиса.
Так как промисы инкапсулируют состояния, зависящие от времени, то есть - ожидание успешного или неуспешного получения некоего значения, сами по себе, для окружающего кода, промисы являются конструкциями, от времени не зависящими. Таким образом, их можно комбинировать, добиваясь предсказуемых результатов, не зависящих от временных характеристик выполняемых внутри них операций.
Более того, как только промис разрешается, своё состояние он уже никогда не меняет. В этот момент он становится неизменяемым (иммутабельным) объектом, при этом к нему можно обращаться столько раз, сколько необходимо.
Очень удобно и то, что промисы можно объединять в цепочки:
function delay(time) {
return new Promise(function(resolve, reject) {
setTimeout(resolve, time);
});
}
delay(1000)
.then(function() {
console.log("after 1000ms");
return delay(2000);
})
.then(function() {
console.log("after another 2000ms");
})
.then(function() {
console.log("step 4 (next Job)");
return delay(5000);
})
// ...
Вызов delay(2000) создаёт промис, который будет разрешён через 2000 мс., затем мы возвращаем этот промис из коллбэка успешного завершения операции в первом then(...), что приводит к тому, что промис второго then(...) будет ожидать эти 2000 мс.
Обратите внимание на то, что так как промисы, после разрешения, не подлежат модификации внешними средствами, теперь безопасно передавать эти значения любым программным механизмам, не опасаясь того, что они будут случайно или злонамеренно изменены. Это особенно актуально в случае, если имеется несколько конструкций, наблюдающих за промисом и ожидающих его разрешения. Любая из этих конструкций не может помешать другим ожидать разрешения промиса. Разговоры об иммутабельности, могут показаться слишком теоретизированными, но это, на самом деле, один из важных базовых аспектов устройства промисов, поэтому неправильно будет обойти его вниманием.
- Промис или нет?
Важная деталь, касающаяся работы с промисами, заключается в точном знании того, является ли некое значение объектом Promise или нет. Другими словами, речь идёт о том, чтобы знать, будет ли некое значение вести себя как промис.
Известно, что промисы можно создавать с использованием конструкции new Promise(...), в результате, можно подумать, что проверки вида p instanceof Promise будет достаточно. Однако, это не совсем так.
Дело в том, что получить промис можно из другого браузерного окна (то есть, из фрейма), в котором промисы создаются с помощью его собственного конструктора Promise, отличного от того, который используется в текущем окне или фрейме. Как результат, вышеописанная проверка не сможет получить ответ на вопрос о том, является ли некое значение промисом.
Более того, в некоей библиотеке или каком-нибудь фреймворке могут использоваться их собственные промисы, а не те, что реализованы в ES6. На самом деле, можно даже использовать промисы, созданные с помощью библиотек, в старых версиях браузеров, которые и не подозревают о существовании стандартных промисов.
- Проглатывание исключений
Если в любом месте при создании промиса или при ожидании его разрешения возникнет исключение, вроде TypeError или ReferenceError, это исключение будет перехвачено и приведёт к отклонению промиса.
Например:
var p = new Promise(function(resolve, reject) {
foo.bar();
// 'foo' не определено, поэтому возникает ошибка!
resolve(374); // сюда мы не попадём никогда :(
});
p.then(
function fulfilled() {
// сюда мы тоже не попадаем :(
},
function rejected(err) {
// 'err' будет объектом исключения TypeError из строки foo.bar()
}
);
Но что произойдёт, если промис разрешён, но на стадии получения его результата возникнет JS-исключение (в коллбэке, зарегистрированном then(...))? Даже хотя такая ошибка и не будет потеряна, можно обнаружить, что обрабатывается эта ситуация, на первый взгляд, несколько неожиданно:
var p = new Promise(function(resolve, reject) {
resolve(374);
});
p.then(function fulfilled(message) {
foo.bar();
console.log(message); // этого фрагмента достичь не удаётся
},
function rejected(err) {
// этого тоже
}
);
Кажется, будто исключение, вызванное строкой foo.bar() и в самом деле было "проглочено". Однако, это не так. На более глубоком уровне оказывается, что возникает нечто, чего мы не ожидаем. А именно, сам вызов p.then(...) возвращает другой промис, и именно этот промис будет отклонён с исключением TypeError.
- Обработка неперехваченных исключений
Есть и другие подходы к работе с исключениями, которые многие сочли бы более удачными.
Часто можно встретить предложения, заключающиеся в том, что при работе с промисами следует использовать блок done(...), который сообщает о том, что обработка цепочки промисов "завершена". Блок done(...) не создаёт и не возвращает промисы, поэтому коллбэк, переданный done(...), очевидно, не связан с сообщениями об ошибках, передаваемых присоединённым промисам, которых не существует.
Он обрабатывается, так, как и можно обычно ожидать от ситуации, в которой возникают неперехваченные ошибки: любое исключение внутри обработчика отклонения промиса в done(...) будет выброшено как глобальная необработанная ошибка (обычно сообщение об этом попадает в консоль разработчика):
var p = Promise.resolve(374);
p.then(function fulfilled(msg) {
// у числа нет строковых функций, поэтому тут будет выброшена ошибка
console.log(msg.toLowerCase());
})
.done(null, function() {
// если здесь произойдёт исключение, оно попадёт в глобальную область видимости
});
- Новшество ES8: async / await
В JavaScript ES8 появилась конструкция async / await, которая упрощает работу с промисами. Сейчас мы кратко рассмотрим возможности, которые предлагает async / await и поговорим о том, как использовать эти возможности для написания асинхронного кода.
Асинхронные функции объявляют, пользуясь ключевым словом async. Такая функция возвращает объект AsyncFunction. Этот объект представляет собой асинхронную функцию, которая выполняет код, находящийся внутри неё.
Когда асинхронная функция вызывается, она возвращает объект Promise. Если такая функция возвращает значение, которое не является объектом Promise, этот объект будет автоматически создан и разрешён с использованием значения, возвращённого функцией. Если функция, объявленная с ключевым словом async, выдаст исключение, промис будет отклонён с этим исключением.
Функция, объявленная с ключевым словом async, может содержать выражение с ключевым словом await, которое приостанавливает выполнение функции и ожидает разрешения промиса, фиругирующего в данном выражении. После этого выполнение async-функции продолжается, и, например, осуществляется возврат полученного после разрешения промиса значения.
Объекты Promise в JavaScript можно рассматривать как эквиваленты Future из Java или задач из C#.
Цель async / await заключается в том, чтобы упростить использование промисов.
Взглянем на следующий пример:
// Это - самая обыкновенная JS-функция
function getNumber1() {
return Promise.resolve('374');
}
// Эта функция делает то же самое, что и getNumber1
async function getNumber2() {
return 374;
}
Функции, которые выдают исключения, аналогичны функциям, которые возвращают отклонённые промисы:
function f1() {
return Promise.reject('Some error');
}
async function f2() {
throw 'Some error';
}
Ключевое слово await можно использовать только в функциях, объявленных с ключевым словом async. Оно позволяет организовать ожидание разрешения промиса. Если мы используем промисы за пределами async-функций, нам всё ещё нужно использовать коллбэки блока then:
async function loadData() {
// rp - это функция request-promise.
var promise1 = rp('https://api.example.com/endpoint1');
var promise2 = rp('https://api.example.com/endpoint2');
// В данный момент выполняются оба запроса
// и нам нужно подождать их завершения.
var response1 = await promise1;
var response2 = await promise2;
return response1 + ' ' + response2;
}
// Так как мы больше не в функции, объявленной с ключевым словом async
// нам нужно использовать then с возвращённым объектом Promise
loadData().then(() => console.log('Done'));
Определять асинхронные функции можно и используя "асинхронное функциональное выражение", оно очень похоже на обычное определение с использованием инструкции function и имеет почти такой же синтаксис. Основное различие между функциональным выражением и обычным объявлением функции заключается в имени функции, которое, в функциональном выражении, может быть опущено, что приведёт к созданию анонимной функции. Асинхронное функциональное выражение может быть использовано как IIFE (Immediately Invoked Function Expression, немедленно вызываемое функциональное выражение), которое выполняется сразу после его определения.
Выглядит это так:
var loadData = async function() {
// rp - это функция request-promise.
var promise1 = rp('https://api.example.com/endpoint1');
var promise2 = rp('https://api.example.com/endpoint2');
// В данный момент выполняются оба запроса
// и нам нужно подождать их завершения.
var response1 = await promise1;
var response2 = await promise2;
return response1 + ' ' + response2;
}
Стоит отметить, что конструкция async / await поддерживается во всех основных браузерах. Если нужный вам браузер не поддерживает эту технологию, есть и обходные пути, например - Babel и TypeScript.
- 5 советов по написанию надёжного асинхронного кода, который легко поддерживать
- Чистота кода
Использование конструкции async / await позволяет вам писать гораздо меньше кода. Каждый раз, используя async / await, вы избавляетесь от нескольких ненужных шагов. Среди них - использование блока .then(), создание анонимной функции для обработки ответа, задание в этой функции-коллбэке имени для переменной, содержащей результаты ответа, и так далее.
Вот фрагмент кода, в котором используются промисы:
// rp - это функция request-promise.
rp('https://api.example.com/endpoint1').then(function(data) {
// …
});
Вот то же самое, написанное с использованием async / await:
// rp - это функция request-promise.
var response = await rp('https://api.example.com/endpoint1');
- Обработка ошибок
Конструкция async / await позволяет обрабатывать синхронные и асинхронные ошибки с использованием одних и тех же механизмов. А именно, речь идёт о широко известном выражении try / catch.
Взглянем на то, как обработка ошибок выполняется при использовании промисов. В частности, здесь нам приходится использовать блок .catch() для обработки асинхронных ошибок, и блок try / catch для обработки синхронных ошибок:
function loadData() {
try { // Перехват синхронных ошибок.
getJSON().then(function(response) {
var parsed = JSON.parse(response);
console.log(parsed);
}).catch(function(e) { // Перехват асинхронных ошибок
console.log(e);
});
} catch(e) {
console.log(e);
}
}
Вот как обрабатывать ошибки при использовании async / await:
async function loadData() {
try {
var data = JSON.parse(await getJSON());
console.log(data);
} catch(e) {
console.log(e);
}
}
- Обработка условий
Применение async / await упрощает написание кода, использующего условия. Вот - код, основанный на промисах:
function loadData() {
return getJSON()
.then(function(response) {
if (response.needsAnotherRequest) {
return makeAnotherRequest(response)
.then(function(anotherResponse) {
console.log(anotherResponse)
return anotherResponse
})
} else {
console.log(response)
return response
}
})
}
Вот - пример с async / await:
async function loadData() {
var response = await getJSON();
if (response.needsAnotherRequest) {
var anotherResponse = await makeAnotherRequest(response);
console.log(anotherResponse)
return anotherResponse
} else {
console.log(response);
return response;
}
}
- Трассировка стека
В отличие от async / await, стек ошибки, возвращённый из цепочки промисов, не содержит сведений о точном месте, в котором произошла ошибка. Вот как это выглядит при использовании промисов:
function loadData() {
return callAPromise()
.then(callback1)
.then(callback2)
.then(callback3)
.then(() => {
throw new Error("boom");
})
}
loadData()
.catch(function(e) {
console.log(err);
// Error: boom at callAPromise.then.then.then.then (index.js:8:13)
});
Вот - то же самое, но с использованием async / await:
async function loadData() {
await callAPromise1()
await callAPromise2()
await callAPromise3()
await callAPromise4()
await callAPromise5()
throw new Error("boom");
}
loadData()
.catch(function(e) {
console.log(err);
// вывод
// Error: boom at loadData (index.js:7:9)
});
- Отладка
Если вы пользовались промисами, то вы знаете, что отладка подобных конструкций - это кошмар. Например, если установить точку останова внутри блока .then и использовать команды отладки вроде "step-over", отладчик не перейдёт к следующему .then, так как он умеет "перешагивать" лишь через синхронный код. С использованием async / await можно переходить по вызовам, в которых используется ключевое слово await так, будто это - обычные синхронные операции.
WebSocket и HTTP/2+SSE. Что выбрать?
- Введение
В наши дни сложные веб-приложения, обладающие насыщенными динамическими пользовательскими интерфейсами, воспринимаются как нечто само собой разумеющееся. А ведь интернету пришлось пройти долгий путь для того, чтобы достичь его сегодняшнего состояния.
В самом начале интернет не был рассчитан на поддержку подобных приложений. Он был задуман как коллекция HTML-страниц, как "паутина" из связанных друг с другом ссылками документов. Всё было, в основном, построено вокруг парадигмы HTTP "запрос/ответ". Клиентские приложения загружали страницы и после этого ничего не происходило до того момента, пока пользователь не щёлкнул мышью по ссылке для перехода на очередную страницу.
Примерно в 2005-м году появилась технология AJAX и множество программистов начало исследовать возможности двунаправленной связи между клиентом и сервером. Однако, все сеансы HTTP-связи всё ещё инициировал клиент, что требовало либо участия пользователя, либо выполнения периодических обращений к серверу для загрузки новых данных.
- "Двунаправленный" обмен данными по HTTP
Технологии, которые позволяют "упреждающе" отправлять данные с сервера на клиент существуют уже довольно давно. Среди них - Push и Comet.
Один из наиболее часто используемых приёмов для создании иллюзии того, что сервер самостоятельно отправляет данные клиенту, называется "длинный опрос" (long polling). С использованием этой технологии клиент открывает HTTP-соединение с сервером, который держит его открытым до тех пор, пока не будет отправлен ответ. В результате, когда у сервера появляются данные для клиента, он их ему отправляет.
Вот пример очень простого фрагмента кода, реализующего технологию длинного опроса:
(function poll() {
setTimeout(function() {
$.ajax({
url: 'https://api.example.com/endpoint',
success: function(data) {
// Делаем что-то с data
// ...
// Рекурсивно выполняем следующий запрос
poll();
},
dataType: 'json'
});
}, 10000);
})();
Эта конструкция представляет собой функцию, которая сама себя вызывает после того, как, в первый раз, будет запущена автоматически. Она задаёт 10-секундный интервал для каждого асинхронного Ajax-обращению к серверу, а после обработки ответа сервера снова выполняется планирование вызова функции.
Ещё одна используемая в подобной ситуации техника - это Flash или составной запрос HXR, и так называемые htmlfiles.
У всех этих технологий одна и та же проблема: дополнительная нагрузка на систему, которую создаёт использование HTTP, что делает всё это неподходящим для организации работы приложений, где требуется высокая скорость отклика. Например, это что-то вроде многопользовательской браузерной "стрелялки" или любой другой онлайн-игры, действия в которой выполняются в режиме реального времени.
- Введение в технологию WebSocket
Спецификация WebSocket определяет API для установки соединения между веб-браузером и сервером, основанного на "сокете". Проще говоря, это - постоянное соединение между клиентом и сервером, пользуясь которыми клиент и сервер могут отправлять данные друг другу в любое время.
Клиент устанавливает соединение, выполняя процесс так называемого рукопожатия WebSocket. Этот процесс начинается с того, что клиент отправляет серверу обычный HTTP-запрос. В этот запрос включается заголовок Upgrade, который сообщает серверу о том, что клиент желает установить WebSocket-соединение.
Посмотрим, как установка такого соединения выглядит со стороны клиента:
// Создаём новое WebSocket-соединение.
var socket = new WebSocket('ws://websocket.example.com');
URL, применяемый для WebSocket-соединения, использует схему ws. Кроме того, имеется схема wss для организации защищённых WebSocket-соединений, что является эквивалентом HTTPS.
В данном случае показано начало процесса открытия WebSocket-соединения с сервером websocket.example.com.
Вот упрощённый пример заголовков исходного запроса.
GET ws://websocket.example.com/ HTTP/1.1 Origin: http://example.com Connection: Upgrade Host: websocket.example.com Upgrade: websocket
Если сервер поддерживает протокол WebSocket, он согласится перейти на него и сообщит об этом в заголовке ответа Upgrade. Посмотрим на реализацию этого механизма с использованием Node.js:
// Будем использовать реализацию WebSocket из
// https://github.com/theturtle32/WebSocket-Node
var WebSocketServer = require('websocket').server;
var http = require('http');
var server = http.createServer(function(request, response) {
// обработаем HTTP-запрос.
});
server.listen(1337, function() { });
// создадим сервер
wsServer = new WebSocketServer({
httpServer: server
});
// WebSocket-сервер
wsServer.on('request', function(request) {
var connection = request.accept(null, request.origin);
// Это - самый важный для нас коллбэк, где обрабатываются сообщения от клиента.
connection.on('message', function(message) {
// Обработаем сообщение WebSocket
});
connection.on('close', function(connection) {
// Закрытие соединения
});
});
После установки соединения в ответе сервера будут сведения о переходе на протокол WebSocket:
HTTP/1.1 101 Switching Protocols Date: Wed, 25 Oct 2017 10:07:34 GMT Connection: Upgrade Upgrade: WebSocket
После этого вызывается событие open в экземпляре WebSocket на клиенте:
var socket = new WebSocket('ws://websocket.example.com');
// Выводим сообщение при открытии WebSocket-соединения.
socket.onopen = function(event) {
console.log('WebSocket is connected.');
};
Теперь, после завершения фазы рукопожатия, исходное HTTP-соединение заменяется на WebSocket-соединение, которое использует то же самое базовое TCP/IP-соединение. В этот момент и клиент и сервер могут приступать к отправке данных.
Благодаря использованию WebSocket можно отправлять любые объёмы данных, не подвергая систему ненужной нагрузке, вызываемой использованием традиционных HTTP-запросов. Данные передаются по WebSocket-соединению в виде сообщений, каждое из которых состоит из одного или нескольких фреймов, содержащих отправляемые данные (полезную нагрузку). Для того, чтобы обеспечить правильную сборку исходного сообщения по достижению им клиента, каждый фрейм имеет префикс, содержащий 4-12 байтов данных о полезной нагрузке. Использование системы обмена сообщениями, основанной на фреймах, помогает сократить число служебных данных, передаваемых по каналу связи, что значительно уменьшает задержки при передаче информации.
Стоит отметить, что клиенту будет сообщено о поступлении нового сообщения только после того, как будут получены все фреймы и исходная полезная нагрузка сообщения будет реконструирована.
- Различные URL протокола WebSocket
Выше мы упоминали о том, что в WebSocket используется новая схема URL. На самом деле - их две: ws:// и wss://.
При построении URL-адресов используются определённые правила. Особенностью URL WebSocket является то, что они не поддерживают якоря (#sample_anchor).
В остальном к URL WebSocket применяются те же правила, что и к URL HTTP. При использовании ws-адресов соединение оказывается незашифрованным, по умолчанию применяется порт 80. При использовании wss требуется TLS-шифрование и применяется порт 443.
- О heartbeat-сообщениях
В любой момент после процедуры рукопожатия, либо клиент, либо сервер, может решить отправить другой стороне ping-сообщение. Получая такое сообщение, получатель должен отправить, как можно скорее, pong-сообщение. Это и есть heartbeat-сообщения. Их можно использовать для того, чтобы проверить, подключён ли ещё клиент к серверу.
Сообщения "ping" и "pong" - это всего лишь управляющие фреймы. У ping-сообщений поле opcode установлено в значение 0x9, у pong-сообщений - в 0xA. При получении ping-сообщения, в ответ надо отправить pong-сообщение, содержащее ту же полезную нагрузку, что и ping-сообщение (для таких сообщений максимальная длина полезной нагрузки составляет 125). Кроме того, вы можете получить pong-сообщение, не отправляя перед этим ping-сообщение. Такие сообщения можно просто игнорировать.
Подобная схема обмена сообщениями может быть очень полезной. Есть службы (вроде балансировщиков нагрузки), которые останавливают простаивающие соединения.
Вдобавок, одна из сторон не может, без дополнительных усилий, узнать о том, что другая сторона завершила работу. Только при следующей отправке данных вы можете выяснить, что что-то пошло не так.
- Обработка ошибок
Обрабатывать ошибки в ходе работы с WebSocket-соединениями можно, подписавшись на событие error. Выглядит это примерно так:
var socket = new WebSocket('ws://websocket.example.com');
// Обработка ошибок.
socket.onerror = function(error) {
console.log('WebSocket Error: ' + error);
};
- Закрытие соединения
Для того, чтобы закрыть соединение, либо клиент, либо сервер, должен отправить управляющий фрейм с полем opcode, установленным в 0x8. При получении подобного фрейма другая сторона, в ответ, отправляет фрейм закрытия соединения. Первая сторона затем закрывает соединение. Таким образом, данные, полученные после закрытия соединения, отбрасываются.
Вот как инициируют операцию закрытия WebSocket-соединения на клиенте:
// Закрыть соединение, если оно открыто.
if (socket.readyState === WebSocket.OPEN) {
socket.close();
}
Кроме того, для того, чтобы произвести очистку после завершения закрытия соединения, можно подписаться на событие close:
// Выполнить очистку.
socket.onclose = function(event) {
console.log('Disconnected from WebSocket.');
};
Серверу нужно прослушивать событие close для того, чтобы, при необходимости, его обработать:
connection.on('close', function(reasonCode, description) {
// Соединение закрывается.
});
- Сравнение технологий WebSocket и HTTP/2
Хотя HTTP/2 предлагает множество возможностей, эта технология не может полностью заменить существующие push-технологии и потоковые способы передачи данных.
Первое, что важно знать об HTTP/2, заключается в том, что это - не замена всего, что есть в HTTP. Виды запросов, коды состояний и большинство заголовков остаются такими же, как и при использовании HTTP. Новшества HTTP/2 заключаются в повышении эффективности передачи данных по сети.
Если сравнить HTTP/2 и WebSocket, мы увидим много общих черт:
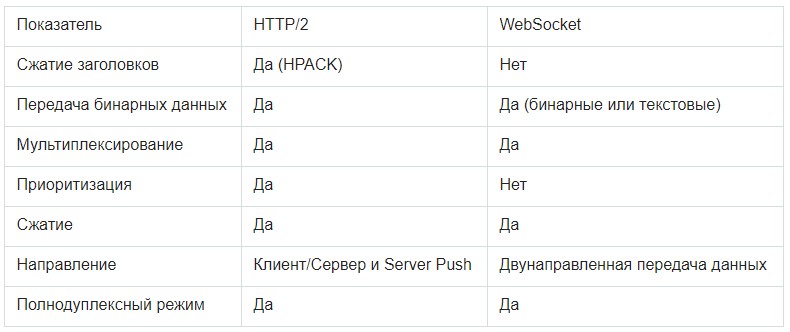
Как уже было сказано, HTTP/2 вводит технологию Server Push, которая позволяет серверу отправлять данные в клиентский кэш по собственной инициативе. Однако, при использовании этой технологии данные нельзя отправлять прямо в приложение. Данные, отправленные сервером по своей инициативе, обрабатывает браузер, при этом нет API, которые позволяют, например, уведомить приложение о поступлении данных с сервера и отреагировать на это событие.
Именно в подобной ситуации весьма полезной оказывается технология Server-Sent Events (SSE). SSE - это механизм, который позволяет серверу асинхронно отправлять данные клиенту после установления клиент-серверного соединения.
После соединения сервер может отправлять данные по своему усмотрению, например, когда окажется готовым к передаче очередной фрагмент данных. Этот механизм можно представить себе как одностороннюю модель издатель-подписчик. Кроме того, в рамках этой технологии существует стандартное клиентское API для JavaScript, называемое EventSource, реализованное в большинстве современных браузеров как часть стандарта HTML5 W3C. Обратите внимание на то, что для браузеров, которые не поддерживают API EventSource, существуют полифиллы.
Так как технология SSE основана на HTTP, она отлично сочетается с HTTP/2. Её можно скомбинировать с некоторыми возможностями HTTP/2, что открывает дополнительные перспективы. А именно, HTTP/2 даёт эффективный транспортный уровень, основанный на мультиплексированных каналах, а SSE даёт приложениям API для передачи данных с сервера.
Для того, чтобы в полной мере понять возможности мультиплексирования и потоковой передачи данных, взглянем на определение IETF: "поток" - это независимая, двунаправленная последовательность фреймов, передаваемых между клиентом и сервером в рамках соединения HTTP/2. Одна из его основных характеристик заключается в том, что одно HTTP/2-соединение может содержать несколько одновременно открытых потоков, причём, любая конечная точка может обрабатывать чередующиеся фреймы из нескольких потоков.
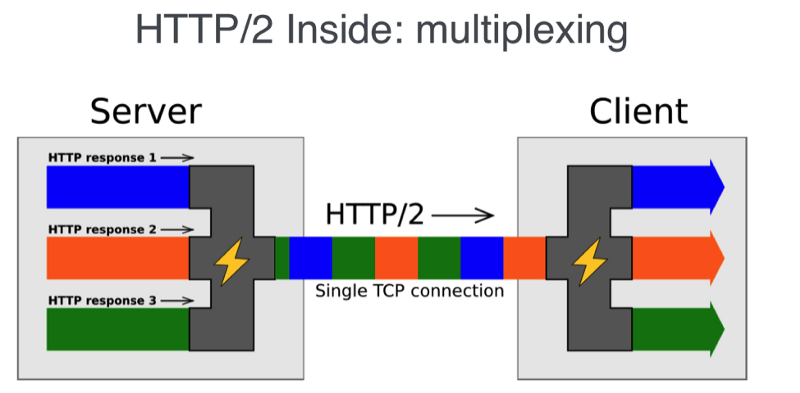
Технология SSE основана на HTTP. Это означает, что с использованием HTTP/2 не только несколько SSE-потоков могут передавать данные в одном TCP-соединении, но то же самое может быть сделано и с комбинацией из нескольких наборов SSE-потоков (отправка данных клиенту по инициативе сервера) и нескольких запросов клиента (уходящих к серверу).
Благодаря HTTP/2 и SSE теперь имеется возможность организации двунаправленных соединений, основанных исключительно на возможностях HTTP, и имеется простое API, которое позволяет обрабатывать в клиентских приложениях данные, поступающие с серверов. Недостаточные возможности в сфере двунаправленной передачи данных часто рассматривались как основной недостаток при сравнении SSE и WebSocket. Благодаря HTTP/2 подобного недостатка больше не существует. Это открывает возможности по построению систем обмена данными между серверными и клиентскими частями приложений исключительно с использованием возможностей HTTP, без привлечения технологии WebSocket.
- WebSocket и HTTP/2. Что выбрать?
Несмотря на чрезвычайно широкое распространение связки HTTP/2+SSE, технология WebSocket, совершенно определённо, не исчезнет, в основном из-за того, что она отлично освоена и из-за того, что в весьма специфических случаях у неё есть преимущества перед HTTP/2, так как она была создана для обеспечения двустороннего обмена данными с меньшей дополнительной нагрузкой на систему (например, это касается заголовков).
Предположим, вы хотите создать онлайн-игру, которая нуждается в передаче огромного количества сообщений между клиентами и сервером. В подобном случае WebSocket подойдёт гораздо лучше, чем комбинация HTTP/2 и SSE.
В целом, можно порекомендовать использование WebSocket для случаев, когда нужен по-настоящему низкий уровень задержек, приближающийся, при организации связи между клиентом и сервером, к обмену данными в реальном времени. Помните, что такой подход может потребовать переосмысления того, как строится серверная часть приложения, а также то, что тут может потребоваться обратить внимание на другие технологии, вроде очередей событий.
Если вам нужно, например, показывать пользователям в реальном времени новости или рыночные данные, или вы создаёте чат-приложение, использование связки HTTP/2+SSE даст вам эффективный двунаправленный канал связи, и, в то же время - преимущества работы с технологиями из мира HTTP. А именно, технология WebSocket нередко становится источником проблем, если рассматривать её с точки зрения совместимости с существующей веб-инфраструктурой, так как её использование предусматривает перевод HTTP-соединения на совершенно другой протокол, ничего общего с HTTP не имеющий. Кроме того, тут стоит учесть соображения масштабируемости и безопасности. Компоненты веб-систем (файрволы, средства обнаружения вторжений, балансировщики нагрузки) создают, настраивают и поддерживают с оглядкой на HTTP. В результате, если говорить об отказоустойчивости, безопасности и масштабируемости, для больших или очень важных приложений лучше подойдёт именно HTTP-среда.
Особенности и сфера применения WebAssembly
- Что такое WebAssembly
WebAssembly (сокращённо - wasm) - это эффективный низкоуровневый байт-код для веб-приложений. Wasm даёт возможность разработки функционала веб-страниц на языках, отличных от JavaScript (например, это C, C++, Rust и другие). Код на этих языках компилируется (статически) в WebAssembly. В результате получается веб-приложение, которое быстро загружается и отличается очень высокой производительностью.
- Время загрузки
Для того, чтобы запустить JavaScript-программу, браузеру сначала нужно загрузить все .js-файлы, которые хранятся и передаются по сети в виде обычного текста.
Wasm - это низкоуровневый язык, похожий на ассемблер. WebAssembly-программы загружаются браузером быстрее, так как через интернет нужно передать уже скомпилированные файлы в весьма компактном бинарном формате.
- Выполнение
Сегодня wasm-программы выполняются лишь на 20% медленнее чем машинный код. Это, без сомнения, достойный результат. Ведь речь идёт о формате, который компилируется в особом окружении и запускается с применением множества ограничений, которые обеспечивают высокий уровень безопасности. Подобное замедление в сравнении с машинным кодом в этом свете выглядит не таким уж и большим. Кроме того, в будущем ожидается повышение производительности wasm-кода. Ещё интереснее то, что wasm платформенно-независим. Его поддержка имеется во всех ведущих браузерных движках, которые демонстрируют примерно одинаковую производительность при выполнении wasm-кода.
- Wasm и JS-движок V8
Вот схема устройства движка V8, а именно, тот путь, который проходит программа на JavaScript от простого текстового файла до исполняемого кода.
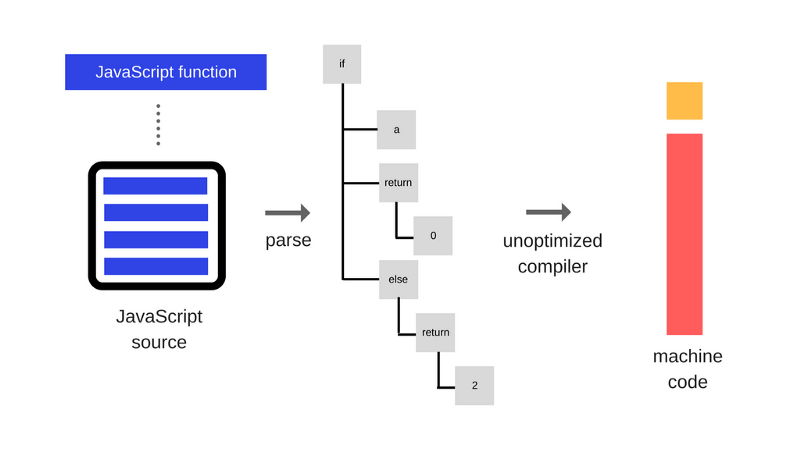
Слева представлен исходный код на JavaScript, который содержит некую функцию. Сначала этот код подвергается парсингу, строки превращаются в токены и генерируется абстрактное синтаксическое дерево (Abstract Syntax Tree, AST). AST - это представление логики JS-программы. После создания AST V8 преобразует то, что получилось, в машинный код. Производится обход абстрактного синтаксического дерева и то, что раньше было функцией, существующей в виде текста, преобразуется в её скомпилированный вариант. При этом V8 не прилагает особых усилий для того, чтобы оптимизировать код.
Посмотрим теперь на то, что происходит на следующих стадиях работы движка.
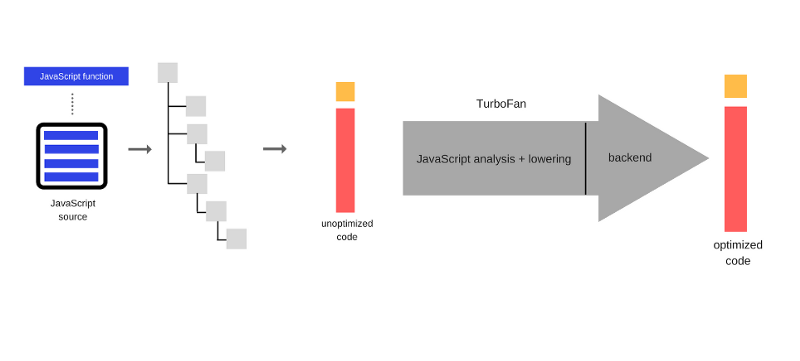
Здесь показано, что теперь приходит время TurboFan - одного из оптимизирующих компиляторов V8. Во время работы JavaScript-приложения в V8 производится множество вспомогательных действий. А именно, TurboFan наблюдает за происходящим в поисках узких мест и наиболее часто используемых фрагментов программы для того, чтобы оптимизировать соответствующие участки кода. После этого TurboFan обработает наиболее ответственные части программы, пропустив их через оптимизирующий JIT-компилятор, что приведёт к тому, что те функции, которые "съедают" большую часть времени процессора, станут выполняться гораздо быстрее.
Этот подход позволяет повысить производительность выполнения JavaScript, решает проблему скорости работы программ, но и тут не всё гладко. Дело в том, что операции по анализу кода и по принятию решений о том, что нужно оптимизировать, а что не нужно, так же потребляют ресурсы. Это, в свою очередь, означает более высокое энергопотребление систем, что, в случае с мобильными устройствами, ведёт к сокращению срока их жизни от одной зарядки.
Если же включить в вышеприведённую схему wasm, то окажется, что этот код не нуждается в анализе и в нескольких проходах компиляции. Он уже оптимизирован и готов к использованию.
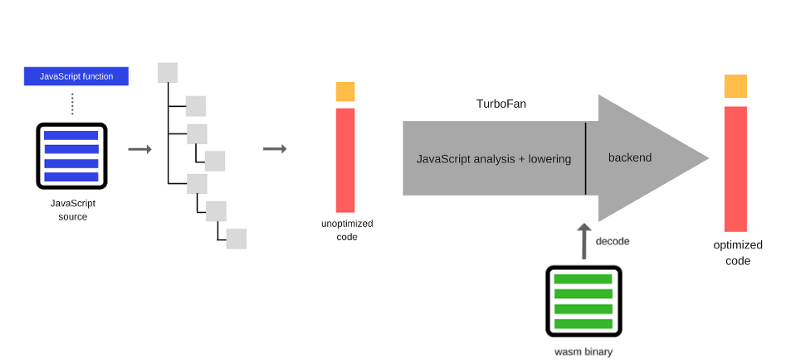
Wasm-код оптимизируется в ходе статической компиляции. При работе с ним не нужно разбирать текстовые файлы. Благодаря wasm в нашем распоряжении оказываются бинарные файлы, которые достаточно лишь преобразовать в машинный код. Все улучшения в этот код были внесены при компиляции, которая производится до того, как он попадает в браузер. Всё это делает выполнение wasm гораздо более эффективным, так как немало шагов по превращению текста программы в оптимизированный машинный код можно пропустить.
- Модель памяти
Память программы, написанной, например, на C++ и скомпилированной в WebAssembly, представляет собой непрерывный блок, в котором нет "дыр". Одна из особенностей wasm, которая способствует повышению безопасности, заключается в отделении стека выполнения от линейного адресного пространства. В C++-программах есть куча, память под стек выделяется в её верхней части. При подобной организации работы с памятью можно, воспользовавшись указателем, получить доступ к памяти стека для того, чтобы воздействовать на состояние переменных, взаимодействие с которыми на текущем этапе выполнения программы не предусмотрено. Именно эту возможность используют многие вредоносные программы.
WebAssembly пользуется совершенно другой моделью работы с памятью. Стек выполнения отделён от памяти, где хранится сама wasm-программа, в результате нет возможности получить несанкционированный доступ к этой памяти, и, например, изменить состояние каких-то переменных. Кроме того, функции используют не указатели, а целочисленные смещения. Здесь применяется механизм косвенной адресации. Необходимые прямые адреса вычисляются в процессе работы программы. Этот механизм построен так, что можно одновременно загрузить несколько wasm-модулей, адреса будут находиться с использованием смещений, в итоге всё будет работать как надо.
- Сборка мусора
В управлении памятью JS-программ участвует сборщик мусора (Garbage Collector, GC).
В случае с WebAssembly всё выглядит немного иначе. Эта технология поддерживают языки с ручным управлением памятью. В результате вместе с wasm-модулями можно использовать и собственный сборщик мусора, но это - непростая задача.
Сейчас WebAssembly ориентирован на способы работы с памятью, применяемые в C++ и Rust. Так как wasm - низкоуровневая технология, вполне логично то, что языки программирования, находящиеся лишь на одну ступень выше ассемблера, будут легко компилироваться в wasm. Так, при программировании на C можно использовать обычную команду malloc, в C++ можно применять интеллектуальные указатели. Rust задействует совершенно другой подход (не будем в это углубляться, так как там всё совершенно иначе). Эти языки не применяют сборщики мусора, в результате им не нужны сложные механизмы времени выполнения, которые отвечают за управление памятью. WebAssembly отлично вписывается в подобные модели работы с памятью.
Кроме того, эти языки не созданы для выполнения сложных операций, которые обычно реализуются с помощью JavaScript, таких, как манипуляции с DOM. Нет смысла писать HTML-приложение целиком на C++, так как C++ просто не рассчитан на такое применение. В большинстве случаев код для веб-приложений на C++ или Rust пишут для работы с WebGL или создают на нём высокооптимизированные библиотеки, например, такие, которые отвечают за математические вычисления.
В будущем, однако, ожидается поддержка языков, которые используют другие модели работы с памятью.
- Доступ к внешним API
В зависимости от среды выполнения, JavaScript программа может напрямую взаимодействовать со специализированными API. Например, если программа написана для браузера, в её распоряжении оказывается набор Web API, которые приложение использует для управления браузером или устройством, и для работы с DOM, CSSOM, WebGL, IndexedDB, Web Audio API и так далее.
У модулей WebAssembly нет прямого доступа к API, который предоставляет платформа. Модули могут взаимодействовать с API только при посредничестве JavaScript. Если, из wasm-модуля, нужно обратиться к подобному API, этот вызов нужно выполнять через JavaScript. Например, если нужно выполнить команду console.log, вызывать её придётся через JS. Подобные обращения к средствам JavaScript сказываются на производительности.
Нельзя говорить, что так будет всегда. В будущем ожидается появление соответствующих API для непосредственного использования их в wasm-коде. Как результат, wasm-приложения можно будет создавать, не используя обращения к JavaScript.
- Карты кода (source maps)
Если после минификации JS-кода его нужно отлаживать, в дело вступают карты кода (source maps). Это - способ установления соответствий между JS-кодом, который минифицирован или скомбинирован из различных файлов, и его исходным состоянием. Когда проект собирают для продакшна, производят минификацию и комбинирование файлов, создают и карту кода, которая хранит информацию об исходных файлах. При обращении к конкретному месту в сгенерированном коде можно, сверившись с картой кода, найти фрагмент исходной программы, который выглядит гораздо понятнее, нежели упакованный вариант программы.
WebAssembly не поддерживает карты кода (source maps), так как пока нет соответствующей спецификации, но, вполне возможно, что уже весьма скоро такая возможность появится.
В результате, при отладке wasm-кода, полученного, например, из C++, можно будет видеть исходный код, устанавливать в нём точки останова. По крайней мере, такова цель внедрения карт кода в wasm.
- Многопоточность
JavaScript выполняется в одном потоке, хотя он поддерживает асинхронную модель программирования. Кроме того, JS поддерживает технологию Web Workers, но у неё довольно специфическая область применения. Преимущественно - вычисления, интенсивно использующие ресурсы процессора, которые могут заблокировать главный поток пользовательского интерфейса. Однако, код Web Workers не может работать с DOM.
В настоящий момент WebAssembly не поддерживает многопоточность. Однако, вероятнее всего, эта возможность появится совсем скоро. Wasm будет близок к низкоуровневым потокам (то есть - тем, которые используются в C++). Возможность работать с "настоящими" потоками создаст множество новых возможностей в разработке браузерных приложений. Но, конечно, многопоточность означает и появление новых сложностей.
- Переносимость кода
JavaScript-приложения могут работать практически везде: в браузерах, на серверах, даже во встраиваемых системах.
WebAssembly спроектирован с учётом безопасности и возможности переносимости кода. Этим он очень похож на JavaScript. Он будет работать в любом окружении, поддерживающем wasm, то есть, например, в любом браузере.
В плане переносимости перед WebAssembly стоят те же цели, которых в своё время пытался достичь Java посредством апплетов.
Веб-воркеры и пять сценариев их использования
- Ограничения асинхронного программирования
Прежде чем мы начнём говорить о веб-воркерах, стоит вспомнить о том, что JavaScript - это однопоточный язык, однако, он поддерживает и возможности асинхронного выполнения кода.
Асинхронное выполнение кода позволяет пользовательскому интерфейсу веб-приложений нормально функционировать, реагировать на команды пользователя. Система "планирует" нагрузку на цикл событий таким образом, чтобы в первую очередь выполнялись операции, связанные с пользовательским интерфейсом.
Хороший пример использования асинхронных методов программирования демонстрирует техника выполнения AJAX-запросов. Так как ожидание ответа способно занять много времени, запросы можно делать асинхронно, при этом, пока клиент ожидает ответа, может выполняться код, не относящийся к запросу.
// Предполагается использование jQuery
jQuery.ajax({
url: 'https://api.example.com/endpoint',
success: function(response) {
// Код, который должен быть выполнен после получения ответа
}
});
Такой подход, однако, демонстрирует следующую проблему: запросы обрабатываются WEB API браузера. Нас же интересует возможность асинхронного выполнения произвольного кода. Скажем, как быть, если код внутри функции обратного вызова интенсивно использует ресурсы процессора?
var result = performCPUIntensiveCalculation();
Если функция performCPUIntensiveCalculation - это не нечто вроде асинхронно выполняемого HTTP-запроса, а код, блокирующий главный поток (скажем, огромный и тяжёлый цикл for), то при однопоточном подходе к JS-разработке у нас нет способа освободить цикл событий и разблокировать интерфейс браузера. Как результат, пользователь не сможет с ним нормально работать.
Это означает, что асинхронные функции смягчают лишь небольшую часть ограничений, связанных с однопоточностью JS.
В некоторых случаях хорошего результата в деле разгрузки главного потока при выполнении ресурсоёмких операций можно достичь с помощью setTimeout. Например, если разбить сложные вычисления на фрагменты, выполняемые в разных вызовах setTimeout, их можно "распределить" по циклу событий, и таким образом, не блокировать пользовательский интерфейс.
Взглянем на простую функцию, которая вычисляет среднее значение для числового массива.
function average(numbers) {
var len = numbers.length,
sum = 0,
i;
if (len === 0) {
return 0;
}
for (i = 0; i < len; i++) {
sum += numbers[i];
}
return sum / len;
}
Этот код можно переписать так, чтобы он "эмулировал" асинхронное выполнение:
function averageAsync(numbers, callback) {
var len = numbers.length,
sum = 0;
if (len === 0) {
return 0;
}
function calculateSumAsync(i) {
if (i < len) {
// Поместим следующий вызов функции в цикл событий.
setTimeout(function() {
sum += numbers[i];
calculateSumAsync(i + 1);
}, 0);
} else {
// Так как достигнут конец массива, мы вызываем коллбэк
callback(sum / len);
}
}
calculateSumAsync(0);
}
При таком подходе мы используем функцию setTimeout, которая планирует выполнение вычислений. Это приводит к размещению в цикле событий функции, выполняющей следующую порцию вычислений, таким образом, что между сеансами выполнения этой функции достаточно времени для других вычислений, в том числе и для тех, которые связаны с пользовательским интерфейсом.
- Веб-воркеры
HTML5 дал нам множество замечательных возможностей, среди которых можно отметить следующие:
- SSE
- Геолокация
- Кэш приложения
- Локальное хранилище
- Технология Drag and Drop
- Веб-воркеры
Веб-воркеры - это потоки, принадлежащие браузеру, которые можно использовать для выполнения JS-кода без блокировки цикла событий.
Это поистине замечательная возможность. Система понятий JavaScript основана на идее однопоточного окружения, а теперь перед нами технология, которая (частично) снимает это ограничение.
Веб-воркеры позволяют разработчику размещать задачи, для выполнения которых требуются длительные и сложные вычисления, интенсивно задействующие процессор, в фоновых потоках, без блокировки пользовательского интерфейса, что позволяет приложениям оперативно реагировать на воздействия пользователя. Более того, нам больше не нужны обходные пути, вроде рассмотренного выше трюка с setTimeout для того, чтобы найти приемлемый способ взаимодействия с циклом событий.
- Обзор веб-воркеров
Веб-воркеры позволяют выполнять тяжёлые в вычислительном плане и длительные задачи без блокировки потока пользовательского интерфейса. На самом деле, при их использовании вычисления выполняются параллельно. Перед нами настоящая многопоточность.
Возможно, вы вспомните о том, что JavaScript - это однопоточный язык программирования. Пожалуй, тут вы должны осознать, что JS - это язык, который не определяет модель потоков. Веб-воркеры не являются частью JavaScript. Они представляют собой возможность браузера, к которой можно получить доступ посредством JavaScript. Большинство браузеров исторически были однопоточными (эта ситуация, конечно, изменилась), и большинство реализаций JavaScript создано для браузеров.
Веб-воркеры не реализованы в Node.js - там есть концепция "кластеров" или "дочерних процессов", а это уже немного другое.
Стоит отметить, что спецификация упоминает три типа веб-воркеров:
- Выделенные воркеры (Dedicated Workers)
- Разделяемые воркеры (Shared Workers)
- Сервис-воркеры (Service Workers)
- Выделенные воркеры
Экземпляры выделенных веб-воркеров создаются главным процессом. Обмениваться данными с ними может только он.
- Разделяемые воркеры
Доступ к разделяемому воркеру может получить любой процесс, имеющий тот же источник, что и воркер (например - разные вкладки браузера, iframe, и другие разделяемые воркеры).
- Сервис-воркеры
Сервис-воркеры - это воркеры, управляемые событиями, зарегистрированные с использованием источника их происхождения и пути. Они могут контролировать веб-страницу, с которой связаны, перехватывая и модифицируя команды навигации и запросы ресурсов, и выполняя кэширование данных, которым можно очень точно управлять. Всё это даёт нам отличные средства управления поведением приложения в определённой ситуации (например, когда сеть недоступна).
Надо отметить, что в этом материале мы будем заниматься выделенными воркерами, именно их мы будем иметь в виду, говоря о "веб-воркерах" или о "воркерах".
- Как работают веб-воркеры
Веб-воркеры реализованы с использованием .js-файлов, которые включаются в страницу с применением асинхронного HTTP-запроса. Эти запросы полностью скрыты от разработчика благодаря Web Worker API.
Воркеры используют механизмы передачи сообщений, характерные для технологий, которые применяются для организации взаимодействия потоков, что позволяет организовать их параллельное выполнение. Они отлично подходят для того, чтобы выполнять тяжёлые вычислительные операции, не замедляя работу пользовательского интерфейса.
Веб-воркеры выполняются в изолированных потоках в браузере. Как результат, код, который они выполняют, должен быть включён в отдельный файл. Это важно запомнить.
Вот как создают веб-воркеры:
var worker = new Worker('task.js');
Если файл task.js существует и к нему есть доступ, браузер создаст новый поток, который асинхронно загрузит этот файл. После того, как загрузка будет завершена, начнётся выполнение кода воркера. Если при попытке загрузки файла браузер получит сообщение об ошибке 404, файл загружен не будет, при этом сообщения об ошибках не выводятся.
Для запуска только что созданного воркера нужно вызвать его метод postMessage:
worker.postMessage();
- Обмен данными с веб-воркером
Для того чтобы страница, создавшая веб-воркер, могла взаимодействовать с ним, нужно использовать либо метод postMessage, либо широковещательный канал передачи данных, представленный объектом BroadcastChannel.
- Метод postMessage
При вызове этого метода более новые браузеры поддерживают, в качестве первого параметра, объект JSON, а в более старых браузерах поддерживается лишь параметр типа String.
Посмотрим на пример того, как страница, создавшая воркер, может обмениваться с ним данными, используя JSON-объект. При передаче строки выглядит всё практически точно так же.
Вот часть HTML-страницы:
<button onclick="startComputation()">Start computation</button>
<script>
function startComputation() {
worker.postMessage({'cmd': 'average', 'data': [1, 2, 3, 4]});
}
var worker = new Worker('doWork.js');
worker.addEventListener('message', function(e) {
console.log(e.data);
}, false);
</script>
Вот содержимое файла с кодом воркера:
self.addEventListener('message', function(e) {
var data = e.data;
switch (data.cmd) {
case 'average':
var result = calculateAverage(data); // Функция, вычисляющая среднее значение числового массива
self.postMessage(result);
break;
default:
self.postMessage('Unknown command');
}
}, false);
Когда нажимают на кнопку, на странице выполняется вызов метода postMessage воркера. Этот вызов передаёт воркеру JSON-объект с ключами cmd и data и соответствующими им значениями. Воркер обработает это сообщение посредством заданного в нём обработчика message.
Когда воркер получает сообщение и понимает, чего от него хотят, он будет выполнять вычисления самостоятельно, не блокируя цикл событий. То, чем занимается воркер, выглядит как стандартная JS-функция. Когда вычисления завершены, их результаты передаются главной странице.
В контексте воркера и self, и this, указывают на глобальное пространство имён для воркера.
Для того чтобы остановить воркер, можно воспользоваться одним из двух способов. Первый заключается в вызове с главной страницы метода worker.terminate(). Второй выполняется внутри воркера и реализуется командой self.close().
- Широковещательный канал передачи данных
Объект BroadcastChannel представляет собой более универсальное API для передачи данных. Он позволяет передавать сообщения, которые можно принять во всех контекстах, имеющих один и тот же источник. Все вкладки браузера, iframe или воркеры, относящиеся к одному источнику, могут передавать и принимать широковещательные сообщения:
// Подключение к широковещательному каналу
var bc = new BroadcastChannel('test_channel');
// Пример отправки сообщения
bc.postMessage('This is a test message.');
// Пример простого обработчика событий, который
// выводит сообщения в консоль
bc.onmessage = function (e) {
console.log(e.data);
}
// Отключение от канала
bc.close();
Вот как выглядит схема взаимодействия различных сущностей с использованием широковещательного канала обмена сообщениями:
Однако тут стоит отметить, что объект BroadcastChannel пока имеет довольно ограниченную поддержку в браузерах.
- Способы отправки сообщений веб-воркерам
Есть два способа отправки сообщений веб-воркерам. Первый заключается в копировании данных, второй - в передаче данных от источника к приёмнику без их копирования. Рассмотрим эти способы работы с сообщениями:
- Копирование сообщения. Сообщение сериализуется, копируется, отправляется, а затем, на принимающей стороне, десериализуется. Страница и воркер не используют общий экземпляр сообщения, поэтому тут мы сталкиваемся с созданием копий данных в каждом сеансе отправки сообщений. Большинство браузеров реализуют эту возможность путём автоматического преобразования передаваемой информации в JSON на стороне передатчика и декодирования этих данных на стороне приёмника. Как можно ожидать, это добавляет значительную нагрузку на систему при отправке сообщений. Чем больше сообщение - тем больше времени займёт его отправка.
- Передача сообщения. При таком подходе оказывается, что отправитель сообщения больше не может использовать сообщение после того, как оно отправлено. При этом передача сообщений выполняется практически мгновенно. Главная особенность этого метода заключается в том, что передать с его помощью можно только объект ArrayBuffer.
- Возможности, доступные веб-воркерам
Веб-воркерам, из-за их многопоточной сущности, доступен лишь ограниченный набор возможностей JavaScript. Вот эти возможности:
- Объект navigator
- Объект location (только для чтения)
- XMLHttpRequest
- setTimeout()/clearTimeout() и setInterval()/clearInterval()
- Кэш приложения
- Импорт внешних скриптов с использованием importScripts()
- Создание других веб-воркеров
- Ограничения веб-воркеров
К сожалению, у веб-воркеров нет доступа к некоторым весьма важным возможностям JavaScript. Среди них следующие:
- DOM (это не потокобезопасно)
- Объект window
- Объект document
- Объект parent
Всё это значит, что веб-воркеры не могут манипулировать DOM (и, таким образом, не могут прямо влиять на пользовательский интерфейс). Поначалу может показаться, что это значительно усложняет использование веб-воркеров, однако со временем, узнав о том, как правильно использовать веб-воркеры, вы начнёте воспринимать их как отдельные "вычислительные машины", в то время как то, что относится к работе с пользовательским интерфейсом, будет выполняться в коде страницы. Воркеры будут выполнять тяжёлые вычисления, и после того, как работа будет завершена, отправлять результаты на страницу, вызывающую их, код которой уже внесёт необходимые изменения в пользовательский интерфейс.
- Обработка ошибок
Как и при работе с любым JS-кодом, в веб-воркерах нужно обрабатывать ошибки. Если ошибка возникает в процессе выполнения воркера, вызывается событие ErrorEvent. Объект ошибки содержит три полезных свойства, которые позволяют понять её суть:
- filename - имя файла, в котором содержится скрипт воркера, вызвавший ошибку
- lineno - номер строки, в которой произошла ошибка
- message - описание ошибки
Вот пример кода для обработки ошибок в веб-воркере:
function onError(e) {
console.log('Line: ' + e.lineno);
console.log('In: ' + e.filename);
console.log('Message: ' + e.message);
}
var worker = new Worker('workerWithError.js');
worker.addEventListener('error', onError, false);
worker.postMessage(); // Запустить воркер без сообщения.
Вот код воркера:
self.addEventListener('message', function(e) {
postMessage(x * 2); // Намеренная ошибка. 'x' не определено.
};
Тут вы можете видеть, как мы создали воркер и назначили ему обработчик события error.
Внутри воркера (второй фрагмент кода) мы намеренно вызываем исключение, умножая x на 2 в то время как x не определено в текущей области видимости. Исключение доходит до исходного скрипта и вызывается обработчик onError, выводящий сведения об ошибке.
- Сценарии использования веб-воркеров
Мы рассказали о сильных и слабых сторонах веб-воркеров. Теперь рассмотрим несколько сценариев их использования:
- Рендеринг трёхмерных сцен. В частности, речь идёт о реализации метода трассировки лучей - техники рендеринга, позволяющей создавать изображения путём отслеживания направления лучей света и определения цвета пикселей. Трассировка лучей использует интенсивные математические вычисления для моделирования особенностей распространения света. При таком подходе реализуются такие эффекты, как отражения и преломления, трассировка лучей позволяет добиться имитировать внешний вид различных материалов, и так далее. Вся эта вычислительная логика может быть вынесена в веб-воркер для того, чтобы она не блокировала поток пользовательского интерфейса. Можно сделать ещё интереснее, а именно, разделить рендеринг изображения между несколькими воркерами (и, соответственно, между несколькими процессорными ядрами).
- Шифрование. Сквозное шифрование становится всё более популярным из за всё возрастающего внимания к регулированию распространения персональных и конфиденциальных данных. Операции шифрования могут быть достаточно продолжительными, особенно если возникает необходимость в частом шифровании больших объёмов данных. Это - весьма адекватный сценарий использования веб-воркера, так как тут не нужен доступ к объектам DOM или нечто подобное. Шифрование - это алгоритмы обработки информации, которым достаточно базовых возможностей JS. Когда шифрование выполняется воркером, это не влияет на работу пользователя с интерфейсом сайта.
- Предварительная загрузка данных. Для того чтобы оптимизировать веб-сайт и улучшить впечатления пользователя от работы с ним, можно использовать веб-воркеры для заблаговременной загрузки и сохранения некоторых данных, которыми можно очень быстро воспользоваться тогда, когда позже в них возникнет необходимость. Веб-воркеры отлично подходят для подобного сценария использования, так как выполняемые ими операции не подействуют на интерфейс приложения, в отличие от предварительной загрузки данных, реализованной средствами главного потока.
- Прогрессивные веб-приложения. Такие приложения должны, даже при ненадёжном сетевом соединении, быстро загружаться. Это означает, что данные нужно хранить в браузере локально. Именно здесь в дело вступает IndexedDB или похожее API. В целом, речь идёт о необходимости обслуживания некоего хранилища данных на стороне клиента. Для того чтобы работать с этим хранилищем, не блокируя пользовательский интерфейс, работу надо организовать в веб-воркере. Тут надо отметить, что, в случае с IndexedDB, существует асинхронное API, которое позволяет не нагружать главный поток и без веб-воркеров, но раньше здесь было синхронное API (которое может появиться снова), которым нужно пользоваться только внутри веб-воркеров.
- Проверка правописания. Простая система проверки правописания работает так: программа считывает файл словаря со списком правильно написанных слов. Из словаря формируется дерево поиска, которое обеспечивает эффективный поиск по тексту. Когда системе передают слово для проверки, она проверяет его наличие в дереве поиска. Если слово найти не удаётся, пользователю могут быть предоставлены альтернативные варианты этого слова, полученные путём замены символов исходного слова и поиска полученных слов в дереве на предмет проверки того, являются ли они, с точки зрения системы проверки, правильными. Всё это легко можно вынести в веб-воркер, что даст пользователю возможность работать с текстом, не испытывая проблем, связанных с блокировкой интерфейса при проверке слова и при поиске альтернативных вариантов его написания.
Сервис-воркеры
- Прогрессивные веб-приложения
Прогрессивные веб-приложения, по всей видимости, будут становиться всё популярнее и распространённее. Они нацелены на то, чтобы пользователь воспринимал их не как обычные веб-страницы, а как нечто вроде классических настольных приложений, которые нормально работают независимо от того, подключен компьютер к интернету или нет.
Отсюда исходит одно из основных требований к прогрессивным веб-приложениям, которое заключается в их надёжном функционировании при отсутствующем или нестабильном сетевом соединении. Сервис-воркеры являются важной технической деталью реализации подобного поведения приложений.
Здесь вы можете видеть упрощённую схему взаимоотношений между приложением, сервис-воркером, кэшем, управлением которым занимается сервис-воркер, и сетевыми ресурсами. В идеале, правильная организация взаимодействия приложения с сервис-воркером и кэшем позволит пользователю нормально работать с приложением даже без подключения к сети.
- Особенности сервис-воркеров
В целом можно сказать, что сервис-воркеры - это разновидность веб-воркеров, а если точнее, то они похожи на разделяемые воркеры. В частности, можно выделить следующие важные особенности сервис-воркеров:
- Они выполняются в собственном глобальном контексте, ServiceWorkerGlobalScope.
- Они не привязаны к конкретной странице.
- Они не имеют доступа к DOM.
Особого внимания API сервис-воркеров заслуживает по той причине, что оно позволяет приложениям поддерживать оффлайновые сценарии работы, давая программисту полный контроль над тем, как приложение взаимодействует с внешними ресурсами.
- Жизненный цикл сервис-воркера
Жизненный цикл сервис-воркера не имеет ничего общего с жизненным циклом веб-страницы. Он включает в себя следующие этапы:
- Загрузка
- Установка
- Активация
- Загрузка
На этом этапе жизненного цикла веб-браузер загружает .js-файл, содержащий код сервис-воркера.
- Установка
Для того чтобы установить сервис-воркер, сначала его нужно зарегистрировать. Это делается в JavaScript-коде. Когда сервис-воркер зарегистрирован, браузеру предлагается запустить установку в фоновом режиме.
Регистрируя сервис-воркер, вы сообщаете веб-браузеру о том, где находится его .js-файл. Взглянем на следующий код:
if ('serviceWorker' in navigator) {
window.addEventListener('load', function() {
navigator.serviceWorker.register('/sw.js').then(function(registration) {
// Успешная регистрация
console.log('ServiceWorker registration successful');
}, function(err) {
// При регистрации произошла ошибка
console.log('ServiceWorker registration failed: ', err);
});
});
}
Тут производится проверка того, поддерживается ли Service Worker API в текущем окружении. Если это API поддерживается, то регистрируется сервис-воркер /sw.js.
Метод register() можно без проблем вызывать каждый раз, когда загружается страница. Браузер самостоятельно выяснит, был ли уже зарегистрирован соответствующий сервис-воркер и правильно обработает повторный запрос на регистрацию.
Важная особенность в работе с методом register() заключается в расположении файла сервис-воркера. В данном случае вы можете видеть, что файл сервис-воркера расположен в корне домена. В результате областью видимости сервис-воркера будет весь домен. Другими словами, этот сервис-воркер будет получать события fetch (о которых мы поговорим ниже), генерируемые всеми страницами из этого домена. Аналогично, если зарегистрировать файл сервис-воркера, расположенный по адресу /example/sw.js, этот сервис-воркер будет видеть лишь события fetch со страниц, URL которых начинается с /example/ (то есть, например, /example/page1/, /example/page2/).
В ходе процесса установки сервис-воркера рекомендуется загрузить и поместить в кэш статические ресурсы. После их кэширования установка веб-воркера будет успешно завершена. Если загрузка не удастся, автоматически будет сделана попытка повторной установки. В результате, после успешной установки веб-воркера, разработчик может быть уверен в том, что все необходимые статические материалы находятся в кэше.
Всё это иллюстрирует тот факт, что нельзя говорить о том, что совершенно необходимо то, чтобы регистрация веб-воркера произошла после события load, но рекомендуется поступать именно так.
Почему? Представим, что пользователь впервые открывает веб-приложение. В этот момент сервис-воркер для этого приложения пока не загружен, более того, браузер не может узнать заранее, будет ли приложение использовать сервис-воркер. Если сервис-воркер будет устанавливаться, браузеру понадобится потратить дополнительные системные ресурсы. Эти ресурсы в противном случае пошли бы на рендеринг веб-страницы. Как результат, запуск процесса установки сервис-воркера может отсрочить загрузку и вывод страницы. Обычно же разработчики стремятся к тому, чтобы как можно быстрее показать пользователю рабочую страницу приложения, но в нашем случае без сервис-воркера приложение не сможет нормально работать.
Обратите внимание на то, что вышеприведённые рассуждения имеют смысл только при разговоре о первом посещении страницы. Если, после установки сервис-воркера, пользователь снова посетит ту же страницу, повторная установка производиться не будет, а значит, не пострадает и скорость показа рабочей страницы. После первого посещения страницы приложения сервис-воркер будет активирован, в результате он сможет обрабатывать события загрузки и кэширования при последующих посещениях веб-приложения. Как результат, приложение будет готово к работе в условиях ограниченного сетевого соединения.
- Активация
После установки сервис-воркера мы переходим к следующему этапу его жизненного цикла - к активации. На этом шаге у разработчика появляется возможность поработать с данными, которые были кэшированы ранее.
После активации сервис-воркер сможет управлять всеми страницами, которые попадают в его область видимости. Тут стоит отметить, что механизмы сервис-воркера не будут действовать на ту страницу, которая его зарегистрировала, до тех пор, пока эта страница не будет перезагружена.
После того, как сервис-воркер получит управление, он может оказаться в одном из следующих состояний:
- Обработка событий. Сервис-воркер ожидает поступления событий fetch и message, которые возникают, когда страницы выполняет сетевые запросы или отправляют сообщения. При поступлении события сервис-воркер его обрабатывает.
- Остановка. Система останавливает сервис-воркер для экономии ресурсов.
- Обработка процесса установки внутри сервис-воркера
Сервис-воркер, после того, как был запущен процесс его регистрации, способен воздействовать на происходящее. В частности, речь идёт об обработчике события install в коде сервис-воркера.
Вот что нужно сделать сервис-воркеру при обработке события install:
- Открыть кэш
- Поместить в кэш необходимые материалы
- Подтвердить кэширование всех необходимых материалов
Вот простой пример обработки события install в сервис-воркере:
var CACHE_NAME = 'my-web-app-cache';
var urlsToCache = [
'/',
'/styles/main.css',
'/scripts/app.js',
'/scripts/lib.js'
];
self.addEventListener('install', function(event) {
// event.waitUntil принимает промис для того, чтобы узнать,
// сколько времени займёт установка, и успешно или нет она завершилась.
event.waitUntil(
caches.open(CACHE_NAME)
.then(function(cache) {
console.log('Opened cache');
return cache.addAll(urlsToCache);
})
);
});
Если все материалы успешно кэшированы, это означает и успешную установку сервис-воркера. Если что-нибудь загрузить не удастся, тогда установка будет признана несостоявшейся. Поэтому следует обращать особое внимание на то, какие данные требуется поместить в кэш.
Тут надо отметить, что обработка события install внутри сервис-воркера необязательна.
- Работа с кэшем в процессе выполнения приложения
Здесь начинается самое интересное. Именно тут мы разберём механизмы перехвата запросов, возврата кэшированных данных и кэширования новых материалов.
После того, как сервис-воркер будет установлен и пользователь перейдёт на другую страницу приложения или обновит страницу, на которой он находится, сервис-воркер начнёт получать события fetch. Вот пример, который показывает, как возвращать кэшированные материалы или выполнять новые запросы, а затем кэшировать результат:
self.addEventListener('fetch', function(event) {
event.respondWith(
// Этот метод анализирует запрос и
// ищет кэшированные результаты для этого запроса в любом из
// созданных сервис-воркером кэшей.
caches.match(event.request)
.then(function(response) {
// если в кэше найдено то, что нужно, мы можем тут же вернуть ответ.
if (response) {
return response;
}
// Клонируем запрос. Так как объект запроса - это поток,
// обратиться к нему можно лишь один раз.
// При этом один раз мы обрабатываем его для нужд кэширования,
// ещё один раз он обрабатывается браузером, для запроса ресурсов,
// поэтому объект запроса нужно клонировать.
var fetchRequest = event.request.clone();
// В кэше ничего не нашлось, поэтому нужно выполнить загрузку материалов,
// что заключается в выполнении сетевого запроса и в возврате данных, если
// то, что нужно, может быть получено из сети.
return fetch(fetchRequest).then(
function(response) {
// Проверка того, получили ли мы правильный ответ
if(!response || response.status !== 200 || response.type !== 'basic') {
return response;
}
// Клонирование объекта ответа, так как он тоже является потоком.
// Так как нам надо, чтобы ответ был обработан браузером,
// а так же кэшем, его нужно клонировать,
// поэтому в итоге у нас будет два потока.
var responseToCache = response.clone();
caches.open(CACHE_NAME)
.then(function(cache) {
// Добавляем ответ в кэш для последующего использования.
cache.put(event.request, responseToCache);
});
return response;
}
);
})
);
});
Вот что тут, в общих чертах, происходит:
- Конструкция event.respondWith() определяет то, как мы будем реагировать на событие fetch. Мы передаём из caches.match() промис, который анализирует запрос и выясняет, имеются ли какие-либо кэшированные ответы на подобный запрос, сохранённые в любом из созданных кэшей.
- Если в кэше найдено то, что нужно, из него извлекается ответ.
- Если в кэше не найдено совпадений - выполняется операция fetch.
- Проверяется статус ответа (нам нужен статус 200). Кроме того, мы проверяем тип ответа, который должен равняться basic, что указывает на то, что это запрос из нашего домена. Запросы к материалам из сторонних источников в этом случае кэшированы не будут.
- Ответ добавляется в кэш.
Объекты запросов и ответов необходимо клонировать, так как они являются потоками. Поток можно обработать лишь один раз. Однако с этими потоками нужно работать и сервис-воркеру, и браузеру.
- Обновление сервис-воркера
Когда пользователь посещает веб-приложение, браузер пытается выполнить повторную загрузку .js-файла, который содержит код сервис-воркера. Этот процесс выполняется в фоне.
Если имеется хотя бы мельчайшее различие между файлом сервис-воркера, который был загружен, и текущим файлом, браузер решит, что в коде воркера произошли изменения. Это означает, что в приложении должен использоваться новый сервис-воркер.
Браузер запустит этот новый сервис-воркер и вызовет событие install. Однако в этот момент за взаимодействие приложения с внешним миром всё ещё отвечает старый воркер. Поэтому новый сервис-воркер окажется в состоянии ожидания.
После того, как будет закрыта текущая открытая страница веб-приложения, старый сервис-воркер будет остановлен браузером, а только что установленный сервис-воркер получит полный контроль над происходящим. В этот момент будет вызвано его событие activate.
Зачем всё это нужно? Для того чтобы избежать проблемы наличия двух версий веб-приложения, выполняющихся одновременно, в разных вкладках браузера. Подобное, на самом деле, встречается весьма часто, и ситуация, в которой разные вкладки находятся под контролем разных веб-воркеров, способна привести к серьёзным ошибкам (например - к использованию различных схем данных при локальном хранении информации).
- Удаление данных из кэша
При обработке события activate новой версии сервис-воркера, обычно занимаются работой с кэшем. В частности, тут удаляют старые кэши. Если сделать это раньше, на этапе установки нового воркера, старый сервис-воркер не сможет нормально работать.
Вот пример того, как можно удалить из кэша файлы, которые не были помещены в белый список (в данном случае белый список представлен записями page-1 и page-2):
self.addEventListener('activate', function(event) {
var cacheWhitelist = ['page-1', 'page-2'];
event.waitUntil(
// Получение всех ключей из кэша.
caches.keys().then(function(cacheNames) {
return Promise.all(
// Прохождение по всем кэшированным файлам.
cacheNames.map(function(cacheName) {
// Если файл из кэша не находится в белом списке, его следует удалить.
if (cacheWhitelist.indexOf(cacheName) === -1) {
return caches.delete(cacheName);
}
})
);
})
);
});
- Использование HTTPS
В ходе разработки веб-приложения сервис-воркеры будут нормально работать на localhost, но после выпуска приложения в продакшн нужно будет использовать HTTPS (пожалуй, если вы ещё не пользуетесь HTTPS, это - весьма веская причина улучшить ситуацию).
Сервис-воркер, который не защищён HTTPS, подвержен атакам посредника, так как злоумышленник сможет перехватывать соединения и создавать фальшивые ответы на запросы приложения. Именно поэтому, для того, чтобы сделать систему безопаснее, разработчик должен регистрировать сервис-воркеры на страницах, которые обслуживаются по HTTPS. В частности, это даёт уверенность в том, что сервис-воркер, загружаемый в браузер, не был модифицирован во время передачи его кода по сети.
- Сценарии использования
Сервис-воркеры открывают дорогу для замечательных возможностей веб-приложений. Вот некоторые из них:
- Push-уведомления. Они позволяют пользователям настраивать периодические уведомления, поступающие из веб-приложений.
- Фоновая синхронизация. Этот механизм даёт возможность откладывать выполнение неких действий до тех пор, пока у пользователя не будет стабильного соединения с интернетом. При использовании системы фоновой синхронизации разработчик может быть уверен в том, что если пользователь, скажем, хочет сохранить изменения документа, отредактированного в веб-приложении без доступа к сети, эти изменения не пропадут.
- Периодическая синхронизация (ожидаемая возможность). Это API, которое предоставляет функционал для управления периодической фоновой синхронизацией.
- Работа с геозонами (ожидаемая возможность). Данная возможность позволяет приложению предоставлять пользователю полезный функционал на базе его географического положения, и, в частности, основываясь на событиях попадания пользователя в заранее заданную область.
Отслеживание изменений в DOM с помощью MutationObserver
- Обзор
MutationObserver - это Web API, предоставляемое современными браузерами и предназначенное для обнаружения изменений в DOM. С помощью этого API можно наблюдать за добавлением или удалением узлов DOM, за изменением атрибутов элементов, или, например, за изменением текстов текстовых узлов. Зачем это нужно?
Есть немало ситуаций, в которых API MutationObserver может оказаться очень кстати. Например:
- Вам нужно уведомить пользователя веб-приложения о том, что на странице, с которой он работает, произошли какие-то изменения.
- Вы работаете над новым интересным JS-фреймворком, который динамически загружает JavaScript-модули, основываясь на изменениях DOM.
- Возможно, вы работаете над WYSIWYG-редактором и пытаетесь реализовать функционал отмены и повтора действий. Воспользовавшись API MutationObserver, вы будете, в любой момент, знать о том, какие изменения произошли на странице, а это означает, что вы легко сможете их отменять.
Выше приведены лишь несколько ситуаций, в которых возможности MutationObserver могут оказаться полезными. На самом деле их гораздо больше.
- Как пользоваться MutationObserver
Использовать MutationObserver в веб-приложениях довольно просто. Нужно создать экземпляр MutationObserver, передав соответствующему конструктору функцию, которая будет вызываться каждый раз, когда в DOM будут происходить изменения. Первый аргумент функции - это коллекция всех произошедших мутаций в виде единого пакета. Для каждой мутации предоставляется информация о её типе и об изменениях, которые она представляет.
var mutationObserver = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
console.log(mutation);
});
});
У созданного объекта есть три метода:
- Метод observe запускает процесс отслеживания изменений DOM. Он принимает два аргумента - узел DOM, за которым нужно наблюдать, и объект с параметрами.
- Метод disconnect останавливает наблюдение за изменениями.
- Метод takeRecords возвращает текущую очередь экземпляра MutationObserver, после чего очищает её.
Вот как включить наблюдение за изменениями:
// Запускаем наблюдение за изменениями в корневом HTML-элементе страницы
mutationObserver.observe(document.documentElement, {
attributes: true,
characterData: true,
childList: true,
subtree: true,
attributeOldValue: true,
characterDataOldValue: true
});
Теперь предположим, что в DOM имеется простейший элемент div:
<div id="sample-div" class="test"> Simple div </div>
Используя jQuery, можно удалить атрибут class из этого элемента:
$("#sample-div").removeAttr("class");
Благодаря тому, что мы начали наблюдение за изменениями, предварительно вызвав mutationObserver.observe(...), и тому, что функция, реагирующая на поступление нового пакета изменений, выводит полученные данные в консоль, мы увидим в консоли содержимое соответствующего объекта MutationRecord:

Тут можно видеть мутации, причиной которых стало удаление атрибута class.
И, наконец, для того, чтобы прекратить наблюдение за DOM после того, как работа завершена, можно сделать следующее:
// Прекратим наблюдение за изменениями mutationObserver.disconnect();
- Альтернативы MutationObserver
Стоит отметить, что механизм наблюдениями за изменениями DOM, который предлагает MutationObserver, не всегда был доступен разработчикам. Чем они пользовались до появления MutationObserver? Вот несколько вариантов:
- Опрос (polling)
- Механизм MutationEvents
- CSS-анимация
- Опрос
Самый простой и незамысловатый способ отслеживания изменений DOM - опрос. Используя метод setInterval можно запланировать периодическое выполнение функции, которая проверяет DOM на предмет изменений. Естественно, использование этого метода значительно снижает производительность веб-приложений.
- MutationEvents
API MutationEvents было представлено в 2000 году. Несмотря на то, что это API позволяет решать возлагаемые на него задачи, события мутации вызываются после каждого изменения DOM, что, опять же, приводит к проблемам с производительностью. Теперь API MutationEvents признано устаревшим и вскоре современные браузеры перестанут его поддерживать.
- CSS-анимация
На самом деле, альтернатива MutationObserver в виде CSS-анимаций может показаться несколько странной. Причём тут анимация? В целом, идея тут заключается в создании анимации, которая будет вызвана после того, как элемент будет добавлен в DOM. В момент запуска анимации будет вызвано событие animationstart. Если назначить обработчик для этого события, можно узнать точное время добавления нового элемента в DOM. Время выполнения анимации при этом должно быть настолько маленьким, чтобы она была практически незаметна для пользователя.
Движки рендеринга веб-страниц и советы по оптимизации их производительности
- Обзор
Создавая веб-приложения, мы не пишем изолированный JS-код, который занимается исключительно какими-то собственными «внутренними» делами. Этот код выполняется в окружении, предоставляемом ему браузером, взаимодействует с ним. Понимание устройства этого окружения, того, как оно работает, из каких частей состоит, позволяет разработчику создавать более качественные программы, даёт ему возможность предусмотреть возникновение возможных проблем с приложением, которое вышло в свет.
На рисунке ниже показаны основные компоненты браузера. Давайте поговорим о том, какую роль они играют в процессе обработки веб-страниц.
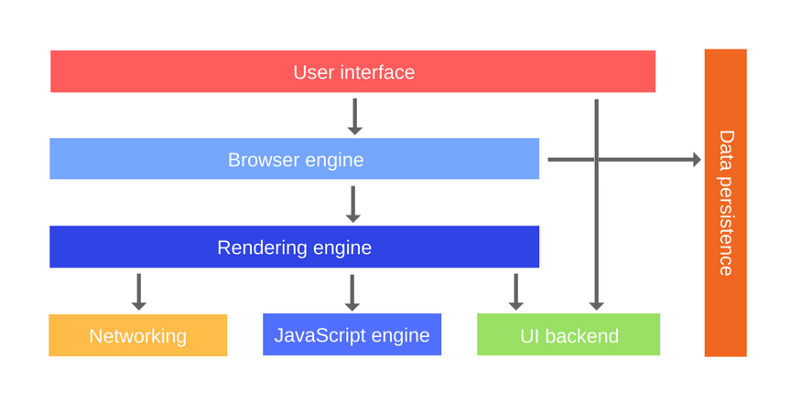
Основные компоненты браузера
- Пользовательский интерфейс (User Interface). Этот компонент браузера включает в себя адресную строку, кнопки «Вперёд» и «Назад», команды для работы с закладками, и так далее. В целом, это всё то, что выводит на экран браузер - за исключением той области его окна, где находится отображаемая им веб-страница.
- Движок браузера (Browser Engine). Он занимается поддержкой взаимодействия между пользовательским интерфейсом и движком рендеринга.
- Движок рендеринга (Rendering Engine). Эта подсистема отвечает за показ веб-страницы. Движок рендеринга обрабатывает HTML и CSS и выводит то, что у него получилось, на экран.
- Сетевая подсистема (Networking). Эта подсистема ответственна за сетевое взаимодействие браузера с внешним миром, в частности, например, её средствами выполняются XHR-запросы. Она поддерживает платформенно-независимый интерфейс, за которым скрываются конкретные реализации различных сетевых механизмов, специфичные для различных платформ.
- Подсистема поддержки пользовательского интерфейса (UI Backend). Эта подсистема отвечает за вывод базовых компонентов интерфейса, таких, как окна и элементы управления, вроде чекбоксов. Здесь браузеру предоставляется универсальный интерфейс, не зависящий от платформы, на которой он работает, а в основе этой подсистемы лежат возможности формирования элементов пользовательского интерфейса, предоставляемые конкретной операционной системой.
- JavaScript-движок (JavaScript Engine). Здесь осуществляется выполнение JS-кода.
- Подсистема постоянного хранения данных (Data Persistence). Если приложению нужны возможности локального хранения данных, оно может пользоваться различными механизмами, предоставляемыми этой подсистемой. Среди них, например, такие API, как localStorage, IndexedDB, WebSQL и FileSystem.
В этом материале мы сосредоточимся на движке рендеринга. Именно эта подсистема браузера занимается разбором и визуализацией HTML и CSS. А это - именно те технологии, с которыми постоянно взаимодействует код веб-приложений, написанный на JavaScript.
- О различных движках рендеринга
Главная задача движка рендеринга заключается в том, чтобы вывести запрошенную страницу в окне браузера. Движок может выводить HTML-документы, XML-документы, изображения. При использовании дополнительных плагинов движок может визуализировать и материалы других типов, например - PDF-документы.
Мы знаем, что существуют различные JS-движки, которые используют различные браузеры. То же самое справедливо и для движков рендеринга. Вот несколько популярных движков:
- Gecko - используется в браузере Firefox
- WebKit - применяется в браузере Safari
- Blink - интегрирован в браузеры Chrome и Opera (с 15-й версии)
- Процесс рендеринга веб-страницы
Движок рендеринга получает содержимое запрошенного документа от сетевого уровня браузера. Процесс рендеринга выглядит так, как показано на рисунке ниже.
Процесс рендеринга веб-страницы. Вот основные этапы этого процесса:
- Обработка HTML для создания дерева DOM.
- Создание дерева рендеринга.
- Расчёт параметров расположения элементов дерева рендеринга на экране, формирование макета страницы.
- Визуализация (отрисовка) дерева рендеринга.
Рассмотрим эти и другие шаги, выполняемые при визуализации веб-страниц, подробнее.
- Создание дерева DOM
Первый этап работы движка рендеринга заключается в разборе HTML-документа и преобразовании того, что у него получилось, в узлы DOM, размещённые в дереве DOM. При этом веб-страница, которая представлена в виде HTML-кода, преобразуется в структуру, подобную той, которая показана на рисунке ниже.
Дерево DOM. Каждый элемент этого дерева, содержащий вложенные элементы, является для них родительским. Это справедливо для всех уровней вложенности.
- Создание дерева CSSOM
CSSOM (CSS Object Model) - это объектная модель CSS. Когда браузер занимается созданием дерева DOM страницы, он находит в разделе head тег link, который ссылается на внешний CSS-файл, скажем, имеющий имя theme.css. Ожидая, что этот ресурс может понадобиться ему для рендеринга страницы, браузер выполняет запрос на загрузку данного файла. Этот файл содержит в себе обычный текст, представляющий собой описание стилей, применяемых к элементам страницы.
Как и в случае с HTML, движку нужно конвертировать CSS в нечто, с чем может работать браузер - в CSSOM. В результате получается дерево CSSOM, представленное на следующем рисунке.
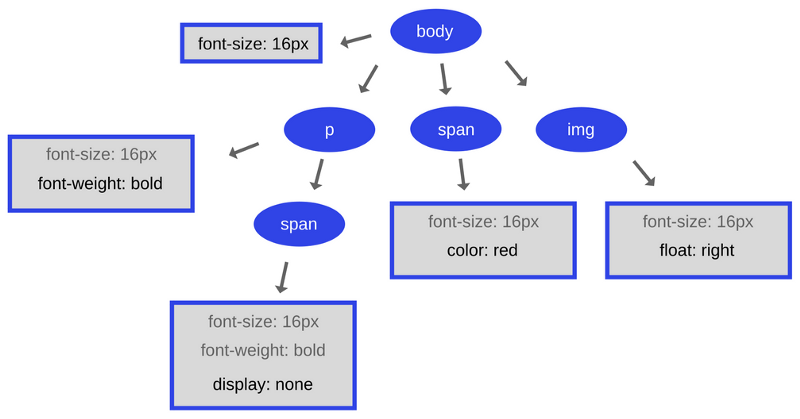
Дерево CSSOM. Знаете, почему CSSOM имеет древовидную структуру? Когда выполняется формирование итогового набора стилей для элемента страницы, браузер начинает с наиболее общих правил, применимых к этому элементу, представленному узлом DOM (например, если узел является потомком элемента body, к нему применяются все стили, заданные для body), а затем рекурсивно уточняет вычисленные стили, применяя более специфические правила.
Разберём пример, который представлен на предыдущем рисунке. Любой текст, содержащийся внутри тега span, который помещён в элемент body, выводится красным цветом и имеет размер шрифта, равный 16px. Эти стили унаследованы от элемента body. Если элемент span является потомком элемента p, значит его содержимое не выводится в соответствии с применённым к нему более специфичным стилем.
Кроме того, обратите внимание на то, что вышеприведённое дерево не является полным CSSOM-деревом. Тут показаны лишь стили, которые мы, в нашем CSS-файле, решили переопределить. У каждого браузера имеется стандартный набор стилей, применяемый по умолчанию, известный ещё как «стили пользовательского агента» (user agent styles). Именно результаты применения этих стилей можно видеть на странице, не имеющей связанных с ней CSS-правил. Наши же стили просто переопределяют некоторые из стандартных стилей браузера.
- Создание дерева рендеринга
Инструкции о внешнем виде элементов, представленные в HTML, скомбинированные с информацией об их стилизации из дерева CSSOM, используются для формирования дерева рендеринга.
Что это такое? Это - дерево визуальных элементов, созданных в том порядке, в котором они будут выводиться на экран. Это - визуальное представление HTML-кода страницы, отражающее влияние соответствующих этой странице CSS-правил. Цель этого дерева заключается в том, чтобы обеспечить вывод элементов правильном порядке.
Узел дерева рендеринга известен в движке WebKit как «renderer» или «render object» (мы будем называть их «объектами рендеринга»).
Вот как будет выглядеть дерево рендеринга для деревьев DOM и CSSOM, показанных выше.
Дерево рендеринга. Вот общее описание действий браузера, выполняемых им при создании дерева рендеринга.
- Начиная с корня дерева DOM, браузер обходит каждый видимый узел. Некоторые узлы невидимы (например - теги, содержащие ссылки на скрипты, мета-теги, и так далее), их браузер пропускает, так как они не влияют на внешний вид страницы. Некоторые узлы скрыты средствами CSS, браузер так же не включает их в дерево рендеринга. Например, узел span из нашего примера не выводится в дереве рендеринга, так как у нас имеется явным образом заданное правило, устанавливающего для него свойство display: none.
- Для каждого видимого узла браузер находит подходящие CSSOM-правила и применяет их.
- В результате формируется структура, содержащая видимые узлы и вычисленные для них стили.
- Формирование макета страницы
После того, как объект рендеринга создан и добавлен в дерево, ему пока ещё не назначены позиция и размер. Вычисление этих значений и называется формированием макета страницы.
HTML использует потоковую модель компоновки. Это означает, что чаще всего система может вычислить геометрические параметры элементов за один проход. Тут используется координатная система, основанная на корневом объекте рендеринга, в ней применяются координаты left и top.
Формирование макета - это рекурсивный процесс. Он начинается в корневом объекте, который соответствует элементу документа <html>. Процесс выполняется рекурсивно по всей иерархической структуре объекта рендеринга, производится вычисление размеров и положения для каждого элемента, который в этом нуждается.
Позиция корневого объекта рендеринга - 0,0. Его размеры соответствуют размерам видимой части окна браузера (это называют «областью просмотра», viewport).
Процесс формирования макета означает задание каждому узлу точной позиции, в которой он должен появиться на странице.
- Визуализация дерева рендеринга
На данном этапе осуществляется обход дерева рендеринга и вызов методов paint() объектов рендеринга, которые и выполняют вывод графического представления объектов на экран.
Визуализация, или отрисовка, может быть глобальной или инкрементной (так же выполняется и формирование макета страницы).
- Глобальная отрисовка означает повторный вывод всего дерева рендеринга.
- Инкрементная отрисовка выполняется в ситуации, когда меняются лишь некоторые из объектов рендеринга, причём так, что это не влияет на всё дерево. Подсистема рендеринга делает недействительными прямоугольные области на экране. Это приводит к тому, что операционная система воспринимает их как участки, содержимое которых нужно обновить и сгенерировать для них событие paint. Операционная система выполняет перерисовку областей интеллектуально, объединяя несколько областей в одну.
В целом, важно понимать, что визуализация - это поэтапный процесс. Для улучшения восприятия страницы пользователями движок рендеринга стремится к тому, чтобы вывести страницу на экран как можно скорее. Он не будет ждать до тех пор, пока будет разобран весь HTML, для того, чтобы приступить к формированию дерева рендеринга и к расчёту параметров макета страницы. В результате некоторые части страницы окажутся обработанными и выведенными на экран, в то время как движок рендеринга продолжит работу с оставшимся содержимым страницы, которое поступает из сети.
- Порядок обработки JS-скриптов и CSS-файлов
Разбор и выполнение скрипта осуществляется сразу же после того, как система обработки кода страницы достигнет тега <script>. Обработка документа приостанавливается до тех пор, пока скрипт не будет выполнен. Это означает, что данный процесс выполняется синхронно.
Если скрипт получают из внешнего источника, то сначала он должен быть загружен через сеть (тоже синхронно). Обработка страницы приостанавливается до тех пор, пока загрузка скрипта не будет завершена.
HTML5 позволяет указывать на возможность асинхронной загрузки и обработки скрипта с использованием отдельного потока.
- Оптимизация производительности рендеринга
Если вы хотите оптимизировать своё приложение с учётом особенностей рендеринга страниц, существует пять основных областей, которые вы можете контролировать, и на которые нужно обратить внимание.
- JavaScript. Мы рассказывали о том, как писать оптимизированный JS-код, не блокирующий пользовательский интерфейс, эффективно использующий память и реализующий другие полезные техники. Когда речь идёт о рендеринге, нам нужно учитывать то, как JS-код будет взаимодействовать с элементами DOM на странице. JavaScript может вносить множество изменений в пользовательский интерфейс, особенно если речь идёт об одностраничных приложениях.
- Вычисление стилей. Это - процесс определения того, какое CSS-правило применяется к конкретному элементу с учётом соответствующих этому элементу селекторов. После определения правил осуществляется их применение и вычисление итогового стиля для каждого элемента.
- Формирование макета страницы. После того, как браузер узнает о том, какие стили применяются к элементу, он может приступить к вычислению того, как много места на экране займёт этот элемент, и к нахождению его позиции. Модель макета веб-страницы указывает на то, что одни элементы могут влиять на другие элементы. Например, ширина элемента <body> может влиять на ширину дочерних элементов, и так далее. Всё это означает, что процесс формирования макета - это задача, требующая интенсивных вычислений. Кроме того, вывод элементов выполняется на множество слоёв.
- Отрисовка. Именно здесь выполняется преобразование всего, что было вычислено ранее, в пиксели, выводимые на экран. Этот процесс включает в себя вывод текста, цветов, изображений, границ, теней, и так далее. Речь идёт о каждой видимой части каждого элемента.
- Компоновка. Так как части страницы вполне могут быть выведены на различных слоях, их требуется совместить в едином окне в нужном порядке, что приведёт к правильному выводу страницы. Это очень важно, особенно - для перекрывающихся элементов.
- Оптимизация JS-кода
JavaScript-код часто приводит к изменению того, что можно наблюдать в браузере. Особенно это актуально для одностраничных приложений. Вот несколько советов, касающихся оптимизации JS для улучшения процесса рендеринга страниц.
- Избегайте использования функций setTimeout() и setInterval() для обновления внешнего вида элементов страниц. Эти функции вызывают коллбэк в некоторый момент формирования кадра, возможно, в самом конце. Нам же нужно вызвать команду, приводящую к визуальным изменениям, в начале кадра, и не пропустить его.
- Переносите длительные вычисления в веб-воркеры.
- Используйте для выполнения изменений в DOM микро-задачи, разбитые на несколько кадров. Этим следует пользоваться тогда, когда задача нуждается в доступе к DOM, а доступ к DOM, из веб-воркера, например, получить нельзя. Это означает, что большую задачу нужно разбить на более мелкие и выполнять их внутри requestAnimationFrame, setTimeout, или setInterval, в зависимости от особенностей задачи.
- Оптимизация CSS
Модификация DOM путём добавления и удаления элементов, изменения атрибутов и других подобных действий приведёт к тому, что браузеру придётся пересчитать стили элементов, и, во многих случаях, макет всей страницы, или, по крайней мере, некоторой её части. Для оптимизации процесса рендеринга страницы учитывайте следующее.
- Уменьшите сложность селекторов. Использование сложных селекторов может привести к тому, что работа с ними займёт более 50% времени, необходимого для вычисления стилей элемента, остальное время уйдёт на конструирование самого стиля.
- Уменьшите число элементов, для которых нужно выполнять вычисление стилей. То есть, лучше, если изменение стиля будет направлено на несколько элементов, а не на всю страницу.
- Оптимизация макета
Пересчёт макета страницы может требовать серьёзных системных ресурсов. Для оптимизации этого процесса примите во внимание следующее.
- Уменьшите число ситуаций, приводящих к пересчёту макета. Когда вы меняете стили, браузер выясняет, требуется ли пересчёт макета для отражения этих изменений. Изменения свойств, таких, как ширина, высота, или позиция элемента (в целом, речь идёт о геометрических характеристиках элементов), требуют изменения макета. Поэтому, без крайней необходимости, не меняйте подобные свойства.
- Всегда, когда это возможно, используйте модель flexbox вместо более старых моделей создания макетов. Эта модель работает быстрее, чем другие, что может дать значительный прирост производительности.
- Избегайте модели работы с документом, предусматривающей периодическое изменение параметров элементов и их последующее считывание. В JavaScript доступны параметры элементов DOM (вроде offsetHeight или offsetWidth) из предыдущего кадра. Считывание этих параметров проблем не вызывает. Однако, если вы, до чтения подобных параметров, меняете стиль элемента (например, динамически добавляя к нему какой-то CSS-класс), браузеру потребуется потратить немало ресурсов для того, чтобы применить изменения стиля, создать макет и возвратить в программу нужные данные. Это может замедлить программу, подобного стоит избегать всегда, когда это возможно.
- Оптимизация отрисовки
Часто эта задача отнимает больше всего времени, поэтому важно избегать ситуаций, приводящих к перерисовке страницы. Вот что здесь можно сделать.
- Изменение любого свойства, за исключением трансформаций и изменений прозрачности, приводит к перерисовке. Используйте эти возможности умеренно.
- Если ваши действия вызвали пересчёт макета, это приводит и к вызову перерисовки страницы, так как изменения геометрических параметров элемента ведут и к его визуальным изменениям.
- Уменьшайте области страниц, которые необходимо перерисовывать, грамотно управляя расположением слоёв и анимацией.
Сетевая подсистема браузеров, оптимизация её производительности и безопасности
- Немного истории
В 1969 году была создана компьютерная сеть ARPAnet (Advanced Research Projects Agency Network), объединяющая несколько научных учреждений. Эта была одна из первых сетей с коммутацией пакетов, и первая сеть, в который была реализована модель TCP/IP. Двадцатью годами позже Тим Бернес-Ли предложил проект известный как Всемирная паутина. За годы, которые прошли с запуска ARPAnet, интернет прошёл долгий путь - от пары компьютеров, обменивающихся пакетами данных, до более чем 75 миллионов серверов, примерно 1.3 миллиарда веб-сайтов и 3.8 миллиарда пользователей.
Количество пользователей интернета в мире
Мы поговорим о том, какие механизмы используют браузеры для того, чтобы повысить производительность работы с сетью (эти механизмы скрыты в их недрах, вероятно, вы о них, работая с сетью в JS, даже и не думаете). Кроме того, мы обратим особое внимание на сетевой уровень браузеров и приведём здесь несколько рекомендаций, касающихся того, как разработчик может помочь браузеру повысить производительность сетевой подсистемы, которую задействуют веб-приложения.
- Обзор
При разработке современных веб-браузеров особое внимание уделяется быстрой, эффективной и безопасной загрузке в них страниц веб-сайтов и веб-приложений. Работу браузеров обеспечивают сотни компонентов, выполняющихся на различных уровнях и решающих широкий спектр задач, среди которых - управление процессами, безопасное выполнение кода, декодирование и воспроизведение аудио и видео, взаимодействие с видеоподсистемой компьютера и многое другое. Всё это делает браузеры больше похожими на операционные системы, а не на обычные приложения.
Общая производительность браузера зависит от целого ряда компонентов, среди которых, если рассмотреть их укрупнённо, можно отметить подсистемы, решающие задачи разбора загружаемого кода, формирования макетов страниц, применения стилей, выполнения JavaScript и WebAssembly-кода. Конечно же, сюда входят и система визуализации информации, и реализованный в браузере сетевой стек.
Программисты часто думают, что узким местом браузера является именно его сетевая подсистема. Часто так и бывает, так как все ресурсы, прежде чем с ними можно будет что-то сделать, сначала должны быть загружены из сети. Для того чтобы сетевой уровень браузера был эффективным, ему нужны возможности, позволяющие играть роль чего-то большего, нежели роль простого средства для работы с сокетами. Сетевой уровень даёт нам очень простой механизм загрузки данных, но, на самом деле, за этой внешней простотой скрывается целая платформа с собственными критериями оптимизации, API и службами.
Сетевая подсистема браузера
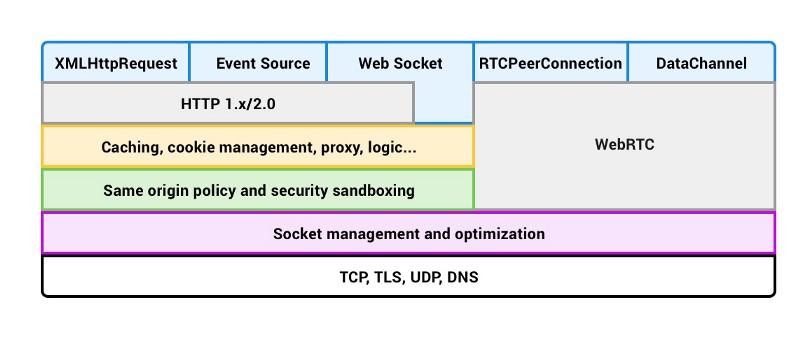
Занимаясь веб-разработкой, мы можем не беспокоиться об отдельных TCP или UDP-пакетах, о форматировании запросов, о кэшировании, и обо всём остальном, что происходит в ходе взаимодействия браузера с сервером. Решением всех этих сложных задач занимается браузер, что даёт нам возможность сосредоточиться на разработке приложений. Однако, знание того, что происходит в недрах браузера, может помочь нам в деле создания более быстрых и безопасных программ.
Поговорим о том, как выглядит обычный сеанс взаимодействия пользователя с браузером. В целом, он состоит из следующих операций:
- Пользователь вводит URL в адресную строку браузера.
- Браузер, получив этот URL, ведущий на какой-либо веб-ресурс, начинает с того, что проверяет собственные кэши, локальный кэш и кэш приложения, для того, чтобы, если там есть то, что нужно пользователю, выполнить запрос, опираясь на локальные копии ресурсов.
- Если кэш использовать не удаётся, браузер берёт доменное имя из URL и запрашивает IP-адрес сервера, обращаясь к DNS. В то же время, если сведения об IP-адресе домена уже есть в кэше браузера, к DNS ему обращаться не придётся.
- Браузер формирует HTTP-пакет, который нужен для того, чтобы запросить страницу с удалённого сервера.
- HTTP-пакет отправляется на уровень TCP, который добавляет в него собственные сведения, необходимые для управления сессией.
- Затем получившийся пакет уходит на уровень IP, основная задача которого заключается в том, чтобы найти способ отправки пакета с компьютера пользователя на удалённый сервер. На этом уровне к пакету так же добавляются дополнительные сведения, обеспечивающие передачу пакета.
- Пакет отправляется на удалённый сервер.
- После того как сервер получает пакет запроса, ответ на этот запрос отправляется в браузер, проходя похожий путь.
Существует браузерное API, так называемое Navigation Timing API, в основе которого лежит спецификация Navigation Timing, подготовленная W3C. Оно позволяет получать сведения о том, сколько времени занимает выполнение различных операций в процессе жизненного цикла запросов. Рассмотрим компоненты жизненного цикла запроса, так как каждый из них серьёзно влияет на то, насколько пользователю будет удобно работать с веб-ресурсом.
Жизненный цикл запроса
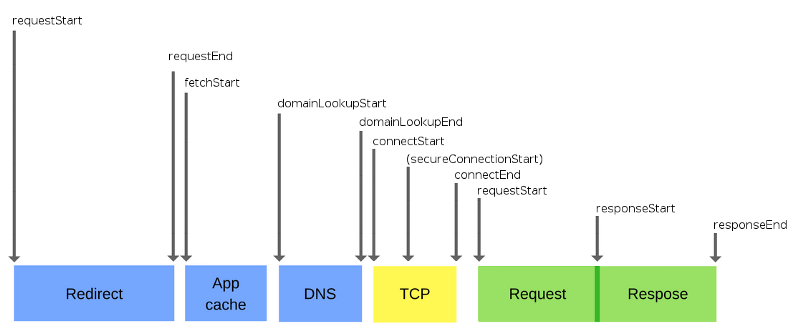
Весь процесс обмена данными по сети очень сложен, он представлен множеством уровней, каждый из которых может стать узким местом. Именно поэтому браузеры стремятся к тому, чтобы улучшить производительность на своей стороне, используя различные подходы. Это помогает снизить, до минимально возможных значений, воздействие особенностей сетей на производительность сайтов.
- Управление сокетами
Прежде чем говорить об управлении сокетами, рассмотрим некоторые важные понятия:
- Источник (origin) - это набор данных, описывающий источник информации, состоящий из трёх частей: протокол, доменное имя и номер порта. Например: https, www.example.com, 443.
- Пул сокетов (socket pool) - это группа сокетов, принадлежащих одному и тому же источнику (все основные браузеры ограничивают максимальный размер пула шестью сокетами).
JavaScript и WebAssembly не позволяют программисту управлять жизненным циклом отдельного сетевого сокета, и, надо сказать, это хорошо. Это не только избавляет разработчика от необходимости работы с низкоуровневыми сетевыми механизмами, но и позволяют браузеру автоматически применять множество оптимизаций производительности, среди которых - повторное использование сокета, приоритизация запросов и позднее связывание, согласование протоколов, принудительное задание ограничений соединений и многие другие.
На самом деле, современные браузеры не жалеют сил на раздельное управление запросами и сокетами. Сокеты организованы в пулы, которые сгруппированы по источнику. В каждом пуле применяются собственные лимиты соединений и ограничения, касающиеся безопасности. Запросы, выполняемые к источнику, ставятся в очередь, приоритизируются, а затем привязываются к конкретным сокетам в пуле. Если только сервер не закроет соединение намеренно, один и тот же сокет может быть автоматически переиспользован для выполнения многих запросов.
Очереди запросов и система управления сокетами
Так как открытие нового TCP-соединения требует определённых затрат системных ресурсов и некоторого времени, переиспользование соединений, само по себе, является отличным средством повышения производительности. По умолчанию браузер использует так называемый механизм "keepalive", который позволяет экономить время на открытии соединения к серверу при выполнении нового запроса. Вот средние показатели времени, необходимого для открытия нового TCP-соединения:
- Локальные запросы: 23 мс.
- Трансконтинентальные запросы: 120 мс.
- Интерконтинентальные запросы: 225 мс.
Такая архитектура открывает возможности для множества других оптимизаций. Например, запросы могут быть выполнены в порядке, зависящем от их приоритета. Браузер может оптимизировать выделение полосы пропускания, распределив её между всеми сокетами, или он может заблаговременно открывать сокеты в ожидании очередного запроса.
Как уже было сказано, всё это управляется браузером и не требует усилий со стороны программиста. Однако это не означает, что программист не может сделать ничего для того, чтобы помочь браузеру. Так, например, выбор подходящих шаблонов сетевого взаимодействия, частоты передачи данных, выбор протокола, настройка и оптимизация серверного стека, могут сыграть значительную роль в повышении общей производительности приложения.
Некоторые браузеры в деле оптимизации сетевых соединений идут ещё дальше. Например, Chrome может "самообучаться" по мере его использования, что ускоряет работу с веб-ресурсами. Он анализирует посещённые сайты и типичные шаблоны работы в интернете, что даёт ему возможность прогнозировать поведение пользователя и предпринимать какие-то меры ещё до того, как пользователь что-либо сделает. Самый простой пример - это предварительный рендеринг страницы в тот момент, когда пользователь наводит указатель мыши на ссылку.
- Сетевая безопасность и ограничения
У того, что браузеру позволено управлять отдельными сокетами, есть, помимо оптимизации производительности, ещё одна важная цель: благодаря такому подходу браузер может применять единообразный набор ограничений и правил, касающихся безопасности, при работе с недоверенными ресурсами приложений. Например, браузер не даёт прямого доступа к сокетам, так как это позволило бы любому потенциально опасному приложению выполнять произвольные соединения с любыми сетевыми системами. Браузер, кроме того, применяет ограничение на число соединений, что защищает сервер и клиент от чрезмерного использования сетевых ресурсов.
Браузер форматирует все исходящие запросы для защиты сервера от запросов, которые могут быть сформированы неправильно. Точно так же браузер относится и к ответам серверов, автоматически декодируя их и принимая меры для защиты пользователя от возможных угроз, исходящих со стороны сервера.
- Процедура TLS-согласования
TLS (Transport Layer Security, протокол защиты транспортного уровня), это криптографический протокол, который обеспечивает безопасность передачи данных по компьютерным сетям. Он нашёл широкое использование во множестве областей, одна из которых - работа с веб-сайтами. Веб-сайты могут использовать TLS для защиты всех сеансов взаимодействия между серверами и веб-браузерами.
Вот как, в общих чертах, выглядит процедура TLS-рукопожатия:
- Клиент посылает серверу сообщение ClientHello, указывая, кроме прочего, список поддерживаемых методов шифрование и случайное число.
- Сервер отвечает клиенту, отправляя сообщение ServerHello, где, кроме прочего, имеется случайное число, сгенерированное сервером.
- Сервер отправляет клиенту свой сертификат, используемый для целей аутентификации, и может запросить подобный сертификат у клиента. Далее, сервер отправляет клиенту сообщение ServerHelloDone.
- Если сервер запросил сертификат у клиента, клиент отправляет ему сертификат.
- Клиент создаёт случайный ключ, PreMasterSecret, и шифрует его открытым ключом из сертификата сервера, отправляя серверу зашифрованный ключ.
- Сервер принимает ключ PreMasterSecret. На его основе сервер и клиент генерируют ключ MasterSecret и сессионные ключи.
- Клиент отправляет серверу сообщение ChangeCipherSpec, указывающее на то, что клиент начнёт использовать новые сессионные ключи для хэширования и шифрования сообщений. Кроме того, клиент отправляет серверу сообщение ClientFinished.
- Сервер принимает сообщение ChangeCipherSpec и переключает систему безопасности своего уровня записей на симметричное шифрование, используя сессионный ключ. Сервер отправляет клиенту сообщение ServerFinished.
- Теперь клиент и сервер могут обмениваться данными приложения по установленному ими защищённому каналу связи. Все эти сообщения будут зашифрованы с использованием сессионного ключа.
Пользователь будет предупреждён в том случае, если верификация окажется неудачной, то есть, например, если сервер использует самоподписанный сертификат.
- Принцип одного источника
В соответствии с принципом одного источника (Same-origin policy), две страницы имеют один и тот же источник, если их протокол, порт (если задан) и хост совпадают.
Вот несколько примеров ресурсов, которые могут быть встроены в страницу с несоблюдением принципа одного источника:
- JS-код, подключённый к странице с использованием конструкции <script src="..."></script>. Сообщения о синтаксических ошибках доступны только для скриптов, имеющих тот же источник, что и страница.
- CSS-стили, подключённые к странице с помощью тега <link rel="stylesheet" href="...">. Благодаря менее строгим синтаксическим правилам, при получении CSS из другого источника, требуется наличие правильного заголовка Content-Type. Ограничения в данном случае зависят от браузера.
- Изображения (тег <img>).
- Медиа-файлы (теги <video> и <audio>).
- Плагины (теги <object>, <embed> и <applet>).
- Шрифты, использующие @font-face. Некоторые браузеры позволяют использование шрифтов из источников, отличающихся от источника страницы, некоторые - нет.
- Всё, что загружается в теги <frame> и <iframe>. Сайт может использовать заголовок X-Frame-Options для предотвращения взаимодействия между ресурсами, загруженными из разных источников.
Вышеприведённый список не является исчерпывающим. Его главная цель - показать принцип "наименьших привилегий". Браузер даёт коду приложения доступ только к тем API и ресурсам, которые ему необходимы. Приложение передаёт браузеру данные и URL, а он форматирует запросы и поддерживает каждое соединение на всём протяжении его жизненного цикла.
Стоит отметить, что не существует единственной концепции "принципа единого источника". Вместо этого имеется набор связанных механизмов, которые применяют ограничения по доступу к DOM, по управлению куки-файлами и состоянием сессии, по работе с сетевыми ресурсами и с другими компонентами браузера.
- Кэширование
Самый лучший, самый быстрый запрос - это запрос, который не ушёл в сеть, а был обработан локально. Прежде чем ставить запрос в очередь на выполнение, браузер автоматически проверяет свой кэш ресурсов, выполняет проверку найденных там ресурсов на предмет актуальности и возвращает локальные копии ресурсов в том случае, если они соответствуют определённому набору требований. Если же ресурсов в кэше нет, выполняется сетевой запрос, а полученные в ответ на него материалы, если их можно кэшировать, помещаются в кэш для последующего использования. В процессе работы с кэшем браузер выполняет следующие действия:
- Он автоматически оценивает директивы кэширования на ресурсах, с которыми ведётся работа.
- Он автоматически, при наличии такой возможности, перепроверяет ресурсы, срок кэширования которых истёк.
- Он самостоятельно управляет размером кэша и удаляет из него ненужные ресурсы.
Управление кэшем ресурсов в стремлении оптимизировать работу с ним - сложная задача. К счастью для нас, браузер берёт эту задачу на себя. Разработчику нужно лишь убедиться в том, что его сервера возвращают подходящие директивы кэширования. Здесь можно почитать подробности о кэшировании ресурсов на клиенте. Кроме того, надеемся, что когда ваши сервера отдают запрошенные ресурсы, они снабжают ответы правильными заголовками Cache-Control, ETag, и Last-Modified.
И, наконец, стоит сказать об ещё одном наборе функций браузера, на который нередко не обращают внимания. Речь идёт об управлении куки-файлами, о работе с сессиями и об аутентификации. Браузеры поддерживают отдельные наборы куки-файлов, разделённые по источникам, предоставляя необходимые API уровня приложения и сервера для чтения и записи куки-файлов, для работы с сессиями и для выполнения аутентификации. Браузер автоматически создаёт и обрабатывает подходящие HTTP-заголовки для того, чтобы автоматизировать все эти процессы.
- Пример
Вот простой, но наглядный пример удобства отложенного управления состоянием сессии в браузере. Аутентифицированная сессия может совместно использоваться в нескольких вкладках или окнах браузера, и наоборот; завершение сессии в одной из вкладок приводит к тому, что сессия окажется недействительной и во всех остальных.
- API и протоколы
Поднимаясь по иерархии сетевых возможностей браузеров, мы наконец прибываем на уровень, на котором находятся API, доступные приложению, и протоколы. Как мы видели, самые низкие уровни предоставляют множество чрезвычайно важных возможностей: управление сокетами и соединениями, обработка запросов и ответов, применение политик безопасности, кэширование, и многое другое. Всякий раз, когда мы инициируем HTTP-запрос, пользуемся механизмом XMLHttpRequest, применяем средства для работы с событиями, посылаемыми сервером, запускаем сессию WebSocket или WebRTC-соединение, мы, фактически, взаимодействуем, как минимум, с некоторыми из этих уровней.
Не существует "самого лучшего протокола" или "самого быстрого API". Любое реальное приложение требует некоей смеси из различных сетевых средств, состав которых определяется различными требованиями. Среди них - особенности взаимодействия с кэшем браузера, системные ресурсы, требующиеся для работы протокола, задержки при передаче сообщений, надёжность соединения, тип передаваемых данных, и многое другое. Некоторые протоколы могут предлагать доставку сообщений с низкой задержкой (например - это механизм работы с событиями, посылаемыми сервером, протокол WebSocket), но не соответствовать другим важным критериям, таким, как возможность задействования кэша браузера или поддержка эффективной передачи бинарных данных при любых вариантах использования.
- Советы по оптимизации производительности и безопасности сетевых подсистем веб-приложений
Вот несколько советов, которые помогут вам повысить производительность и безопасность сетевых подсистем ваших веб-приложений.
- Всегда используйте в запросах заголовок "Connection: Keep-Alive". Браузеры, кстати, используют его по умолчанию. Проверьте, чтобы и сервер использовал тот же самый механизм.
- Используйте подходящие заголовки Cache-Control, Etag и Last-Modified при работе с ресурсами. Это позволит ускорить загрузку страниц при повторных обращениях к ним из того же браузера и сэкономить трафик.
- Потратьте время на настройку и оптимизацию сервера. В этой области, кстати, можно увидеть настоящие чудеса. Помните о том, что процесс подобной настройки очень сильно зависит от особенностей конкретного приложения и от типа передаваемых данных.
- Всегда используйте TLS. В особенности - если в вашем веб-приложении используются какие-либо механизмы аутентификации пользователя.
- Выясните, какие политики безопасности предоставляют браузеры, и используйте их в своих приложениях.
Анимация средствами CSS и JavaScript
- Обзор
Наверняка вы знаете о том, что анимация, помимо чисто утилитарной роли, оказывает огромное влияние на привлекательность веб-приложений. Пользователи всё больше и больше обращают внимание на UX-дизайн проектов, что приводит к тому, что владельцы веб-ресурсов приходят к осознанию важности создания на своих сайтах таких условий, которые позволили бы пользователям комфортно там себя чувствовать. Всё это, помимо визуальной привлекательности страниц и удобства работы с ними, ведёт к тому, что веб-проекты становятся "тяжелее", к тому, что в их интерфейсах растёт число динамических элементов. Всё это требует более сложных анимаций, которые, например, позволяют организовать плавное изменение состояния веб-страниц в ходе работы пользователя с ними. Сегодня анимация не считается чем-то особенным. Пользователи становятся требовательнее, они уже привыкли ожидать наличия у веб-проектов интерактивных отзывчивых интерфейсов.
Однако, анимация интерфейсов - это не так уж и просто. Что анимировать? Когда анимировать? Какие ощущения должна вызывать анимация? Поиск ответов на эти вопросы может потребовать немалых усилий.
- JavaScript-анимация и CSS-анимация
Создавать анимации можно двумя основными способами: с помощью JavaScript, используя API веб-анимации, и средствами CSS. Выбор способа зависит от конкретной задачи, поэтому сразу хочется отметить, что нельзя однозначно говорить о преимуществе одной технологии над другой.
- CSS-анимация
CSS-анимация - это самый простой способ заставить что-либо двигаться по экрану. Начнём с простого примера, демонстрирующего перемещение элемента по осям X и Y. Делается это с помощью CSS-трансформации translate, которая настроена на длительность в 1000 мс.
.box {
-webkit-transform: translate(0, 0);
-webkit-transition: -webkit-transform 1000ms;
transform: translate(0, 0);
transition: transform 1000ms;
}
.box.move {
-webkit-transform: translate(50px, 50px);
transform: translate(50px, 50px);
}
При добавлении класса move значение transform меняется и начинается переход. Помимо длительности, мы можем настраивать динамику анимации (easing). Сущность этой настройки сводится к тому, что она влияет на то, как пользователь воспринимает анимацию. О динамике анимации мы поговорим позже.
Если, как и в предыдущем фрагменте кода, вы создадите отдельные CSS-классы для управления анимацией, затем можно включать и отключать анимацию средствами JavaScript.
Предположим, имеется следующий элемент.
<div class="box">
Sample content.
</div>
С помощью JavaScript можно запускать и останавливать его анимацию.
var boxElements = document.getElementsByClassName('box'),
boxElementsLength = boxElements.length,
i;
for (i = 0; i < boxElementsLength; i++) {
boxElements[i].classList.add('move');
}
В этом фрагменте кода мы берём все элементы, которым назначен класс box и добавляем к ним класс move для того, чтобы запустить их анимацию.
Подобные возможности совместного использования CSS - для описания анимаций, и JS - для её запуска и отключения, делают приложение хорошо сбалансированным. Разработчик может сосредоточиться на управлении состоянием элементов из JavaScript, просто назначая подходящие классы целевым элементам, позволяя браузеру самостоятельно выполнять анимации, описанные средствами CSS.
Для того чтобы сделать элементы веб-интерфейсов динамичнее, в дополнение к использованию CSS-переходов можно воспользоваться CSS-анимациями. Они дают разработчику гораздо больший уровень контроля за отдельными ключевыми кадрами анимации, длительностями этапов анимации и итерациями анимации.
Ключевые кадры используются для того, чтобы сообщить браузеру о том, какие значения CSS-свойства должны иметь в заданные моменты. Браузер самостоятельно находит промежуточные значения для свойств при переходе от одного ключевого кадра к другому.
Рассмотрим пример.
/**
* Это - упрощённая версия без префиксов разработчиков браузеров.
* Если включить их сюда (а в реальном коде это нужно), объём кода значительно возрастёт!
*/
.box {
/* Выберем анимацию */
animation-name: movingBox;
/* Укажем длительность анимации */
animation-duration: 2300ms;
/* Укажем - сколько раз мы хотим повторить анимацию */
animation-iteration-count: infinite;
/* Это приводит к выполнению анимации в обратном порядке на каждой нечётной итерации */
animation-direction: alternate;
}
@keyframes movingBox {
0% {
transform: translate(0, 0);
opacity: 0.4;
}
25% {
opacity: 0.9;
}
50% {
transform: translate(150px, 200px);
opacity: 0.2;
}
100% {
transform: translate(40px, 30px);
opacity: 0.8;
}
}
Применяя CSS-анимации, саму анимацию описывают независимо от целевого элемента, а затем используют свойство animation-name для выбора необходимой анимации.
CSS-анимации, до сих пор, иногда требуют использования префиксов разработчиков браузеров. Так, префикс -webkit- используется в браузерах Safari, Safari Mobile, и в браузере Android. В браузерах Chrome, Opera, Internet Explorer, и Firefox анимации работают без префиксов. Для того чтобы создать CSS-код с префиксами, можно воспользоваться множеством вспомогательных инструментов, что позволяет разработчику, в исходном коде анимаций, обходиться без префиксов.
- JavaScript-анимация
Создавать анимации средствами JavaScript, с применением API веб-анимации, сложнее, чем использовать CSS-переходы и CSS-анимации, но этот подход обычно даёт разработчику гораздо большие возможности.
JS-анимации описывают в коде приложения. Как и любой другой код их можно, например, помещать в объекты. Вот пример JS-кода, который нужно написать для того, чтобы воссоздать описанный выше CSS-переход.
var boxElement = document.querySelector('.box');
var animation = boxElement.animate([
{transform: 'translate(0)'},
{transform: 'translate(150px, 200px)'}
], 500);
animation.addEventListener('finish', function() {
boxElement.style.transform = 'translate(150px, 200px)';
});
По умолчанию применение API веб-анимации модифицирует лишь внешний вид элемента. Если требуется, чтобы объект оставался в той позиции, в которую он был перемещён в ходе анимации, нужно, по завершении анимации, модифицировать его стиль. Именно поэтому в вышеприведённом примере мы прослушиваем событие finish и устанавливаем свойство элемента box.style.transform в значение translate(150px, 200px), которое выражает то же самое, что было сделано с объектом с помощью второй трансформации, выполненной средствами JS.
При использовании JavaScript-анимации разработчик обладает полным контролем над стилями элемента на каждом этапе анимации. Это означает, что анимацию можно замедлять, приостанавливать, останавливать, обращать, как угодно манипулировать элементами. Это особенно полезно в ходе создания сложных приложений, при разработке которых используется объектно-ориентированный подход, так как поведение элементов можно должным образом инкапсулировать.
- Динамика анимации
Естественные перемещения объектов дают пользователям ощущение комфорта при работе с веб-приложениями, что ведёт к более качественному пользовательскому опыту.
Если говорить о том, как объекты движутся в реальном мире, то можно отметить, что они, например, не перемещаются линейно. В физическом мире движущиеся предметы ускоряются и замедляются, так как на них воздействуют самые разные факторы окружающей среды. Человеческий мозг приучен ожидать от объектов подобных перемещений, поэтому, анимируя веб-приложения, следует это учитывать.
Вот пара терминов, которые пригодятся нам при разговоре о динамике анимации. А именно, поговорим о так называемых функциях плавности. Их применение позволяет влиять на динамику анимации.
- ease-in - это функция, при применении которой сначала анимация производится медленно, а затем - постепенно ускоряется.
- ease-out - это функция, при использовании которой анимация начинается быстро, а потом - постепенно замедляется.
Эти функции можно комбинировать. В результате может, например, получиться функция ease-in-out.
Управление динамикой анимации позволяет сделать так, чтобы движение объектов воспринималось как более естественное.
- Ключевые слова для управления динамикой анимации
CSS-переходы и анимации позволяют разработчику выбирать функции плавности. Существуют различные ключевые слова, воздействующие на динамику анимации. Кроме того, можно создавать и собственные функции плавности. Вот несколько ключевых слов, которые можно использовать в CSS для управления динамикой анимации:
- linear
- ease-out
- ease-in
- ease-in-out
Рассмотрим их подробнее для того, чтобы узнать, как они влияют на анимацию.
- Анимация linear
Ключевое слово linear позволяет использовать линейную анимацию. Фактически, эта анимация описывается линейной функцией, при применении которой объект анимируется с постоянной скоростью, без ускорений и замедлений.
Вот как выглядит график линейного CSS-перехода.
Видно, что с течением времени значение равномерно возрастает. Линейные перемещения, однако, воспринимаются как неестественные. В целом, надо отметить, что подобных анимаций стоит избегать.
Вот как выглядит описание такой анимации:
transition: transform 500ms linear;
- Анимация ease-out
Как уже было сказано, применение функции ease-out приводит к высокой скорости анимации в начале процесса (её скорость - выше, чем при применении линейной функции), которая замедляется в конце анимации. Вот как выглядит графическое представление такой анимации.
В целом, подобная анимация лучше подходит для пользовательского интерфейса, так как её быстрое начало даёт ощущение отзывчивости элемента, в то время как замедление в конце анимации также делает её естественнее благодаря наличию неравномерности движения.
Существует множество способов достичь подобного эффекта, но самый простой - воспользоваться ключевым словом ease-out в CSS:
transition: transform 500ms ease-out;
- Анимация ease-in
Эта анимация противоположна той, которую мы только что рассмотрели. Для неё характерна низкая скорость в начале и увеличение скорости в конце. Вот её графическое представление.
В сравнении с анимацией ease-out, анимация ease-in выглядит необычно, так как она даёт ощущение низкого уровня отзывчивости элемента из-за медленного начала. Ускорение в конце так же создаёт странные ощущения, так как скорость анимации с течением времени растёт, в то время как объекты в реальном мире, перед остановкой, обычно снижают скорость.
Для того чтобы воспользоваться этой анимацией, аналогично предыдущим, можно использовать ключевое слово ease-in:
transition: transform 500ms ease-in;
- Анимация ease-in-out
Эта анимация является комбинацией анимаций ease-in и ease-out. Вот как выглядит её график.
Тут стоит отметить, что не рекомендуется использовать анимации, длительность которых слишком велика, так как они создают у пользователя ощущение того, что интерфейс перестал реагировать на его воздействия.
Воспользоваться этой анимацией можно с помощью ключевого слова ease-in-out:
transition: transform 500ms ease-in-out;
- Создание собственных функций плавности
Разработчик может определять собственные функции плавности, которые дают гораздо лучший контроль над тем, какие ощущения у пользователя создают используемые в проекте анимации.
На самом деле, за ключевыми словами, о которых мы говорили выше (ease-in, ease-out, linear), стоят кривые Безье. Уделим им некоторое время, так как именно на них основано создание собственных функций плавности.
- Кривые Безье
Для построения кривой Безье нужно четыре значения, или, говоря точнее - две пары чисел. Каждая пара описывает координаты X и Y опорной точки кубической кривой Безье. Сама кривая начинается в координате (0, 0), а заканчивается - в координате (1, 1). Настраивать можно свойства опорных точек. Значения X координат опорных точек должны находиться в диапазоне [0, 1], значения Y также должны попадать в диапазон [0, 1], хотя надо отметить то, что спецификации не вполне проясняют этот момент.
Даже небольшое изменение значений X и Y координат опорных точек приводит к значительному изменению кривой. Взглянем на пару графиков кривых Безье, опорные точки которых имеют очень близкие, но различающиеся координаты.
Первая кривая Безье
Вторая кривая Безье
Как видите, два этих графика очень сильно отличаются друг от друга. Вот как выглядит описание второй кривой в CSS:
transition: transform 500ms cubic-bezier(0.465, 0.183, 0.153, 0.946);
Первые два числа - это координаты X и Y первой опорной точки, вторая пара - координаты второй.
- Оптимизация производительности анимаций
Анимируя интерфейсы, надо следить за тем, чтобы частота кадров не падала ниже 60 FPS, в противном случае это плохо повлияет на то, как пользователи воспринимают анимированные страницы.
Как и за всё остальное в этом мире, за анимацию надо платить. При этом анимирование некоторых свойств обходится "дешевле", чем анимирование других. Например, анимирование свойств width и height элемента приводит к изменению его геометрии и может привести к тому, что другие элементы на странице переместятся или изменят размер. Этот процесс называется формированием макета страницы.
В целом, следует избегать анимации свойств элементов, которые вызывают изменение макета страницы или её перерисовку. Для большинства современных браузеров это означает ограничение анимациями opacity и transform.
- CSS-свойство will-change
CSS-свойство will-change можно использовать для того, чтобы сообщать браузеру о том, что мы намереваемся изменить свойство элемента. Это позволяет браузеру заранее, до выполнения анимации, применить подходящие оптимизации. Однако не стоит злоупотреблять свойством will-change, так как это приведёт к нерациональной трате ресурсов браузера, что, в свою очередь, приведёт к проблемам с производительностью.
Вот, например, как добавить это свойство для анимаций transform и opacity:
.box {
will-change: transform, opacity;
}
- JavaScript или CSS?
Что выбрать для анимации - API веб-анимации, вызываемое из JS, или CSS? Вероятно, вы помните, что выше мы говорили, что на подобный вопрос нельзя дать однозначного ответа. Однако, для того, чтобы всё-таки определиться с технологией, учтите следующие соображения:
- CSS-анимации и веб-анимации, при наличии их нативной поддержки, обычно обрабатываются потоком композиции (compositor thread). Он отличается от главного потока браузера (main thread), где выполняются задачи по стилизации элементов, по формированию макета, по выводу данных на экран и по выполнению JS-кода. Это означает, что если браузер выполняет какие-то сложные задачи в главном потоке, анимации будут выполняться нормально, без перерывов.
- Анимации transforms и opacity могут быть, во многих случаях, обработаны потоком композиции.
- Если какая-то анимация вызывает перерисовку страницы или изменение макета, поработать придётся главному потоку. Это справедливо и для CSS-анимаций, и для JS-анимаций. Дополнительная нагрузка на систему, вызванная изменением макета или перерисовкой страницы, вероятно, замедлит выполнение задач, решаемых средствами CSS или JavaScript, ставя систему в непростое положение.
Абстрактные синтаксические деревья, парсинг и его оптимизация
- Как устроены языки программирования
Прежде чем говорить об абстрактных синтаксических деревьях, остановимся на том, как устроены языки программирования. Вне зависимости от того, какой именно язык вы используете, вам всегда приходится применять некие программы, которые принимают исходный код и преобразуют его в нечто такое, что содержит конкретные команды для машин. В роли таких программ выступают либо интерпретаторы, либо компиляторы. Неважно, пишете ли вы на интерпретируемом языке (JavaScript, Python, Ruby), или на компилируемом (C#, Java, Rust), ваш код, представляющий собой обычный текст, всегда будет проходить этап парсинга, то есть - превращения обычного текста в структуру данных, которая называется абстрактным синтаксическим деревом (Abstract Syntax Tree, AST).
Абстрактные синтаксические деревья не только дают структурированное представление исходного кода, они, кроме того, играют важнейшую роль в семантическом анализе, в ходе которого компилятор проверяет правильность программных конструкций и корректность использования их элементов. После формирования AST и выполнения проверок эта структура используется для генерирования байт-кода или машинного кода.
- Применение абстрактных синтаксических деревьев
Абстрактные синтаксические деревья используются не только в интерпретаторах и компиляторах. Они, в мире компьютеров, оказываются полезными и во многих других областях. Один из наиболее часто встречающихся вариантов их применения - статический анализ кода. Статические анализаторы не выполняют передаваемый им код. Однако, несмотря на это, им нужно понимать структуру программ.
Предположим, вы хотите разработать инструмент, который находит в коде часто встречающиеся структуры. Отчёты такого инструмента помогут в рефакторинге, позволят уменьшить дублирование кода. Сделать это можно, пользуясь обычным сравнением строк, но такой подход окажется весьма примитивным, возможности его будут ограниченными. На самом деле, если вы хотите создать подобный инструмент, вам не нужно писать собственный парсер для JavaScript. Существует множество опенсорсных реализаций подобных программ, которые полностью совместимы со спецификацией ECMAScript. Например - Esprima и Acorn. Существуют и инструменты, которые могут помочь в работе с тем, что генерируют парсеры, а именно, в работе с абстрактными синтаксическими деревьями.
Абстрактные синтаксические деревья, кроме того, широко используются при разработке транспиляторов. Предположим, вы решили разработать транспилятор, преобразующий код на Python в код на JavaScript. Подобный проект может быть основан на идее, в соответствии с которой используется транспилятор для создания абстрактного синтаксического дерева на основе Python-кода, которое, в свою очередь, преобразуется в код на JavaScript. Вероятно, тут вы зададитесь вопросом о том, как такое возможно. Всё дело в том, что абстрактные синтаксические деревья - это всего лишь альтернативный способ представления кода на некоем языке программирования. Прежде чем код преобразуется в AST, он выглядит как обычный текст, при написании которого следуют определённым правилам, которые формируют язык. После парсинга этот код превращается в древовидную структуру, которая содержит ту же информацию, что и исходный текст программы. В результате можно осуществить не только переход от исходного кода к AST, но и обратное преобразование, превратив абстрактное синтаксическое дерево в текстовое представление кода программы.
- Парсинг JavaScript-кода
Поговорим о том, как строятся абстрактные синтаксические деревья. В качестве примера рассмотрим простую JavaScript-функцию:
function foo(x) {
if (x > 10) {
var a = 2;
return a * x;
}
return x + 10;
}
Парсер создаст абстрактное синтаксическое дерево, которое схематично представлено на следующем рисунке.
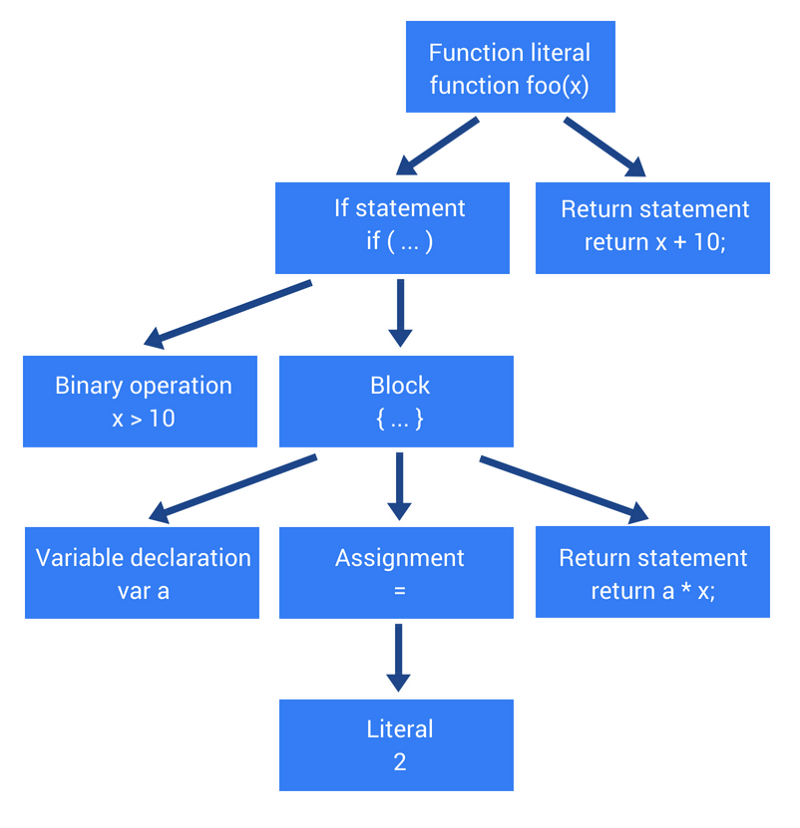
Абстрактное синтаксическое дерево
Обратите внимание на то, что это - упрощённое представление результатов работы парсера. Настоящее абстрактное синтаксическое дерево выглядит гораздо сложнее. В данном случае наша главная цель - получить представление о том, во что, в первую очередь, превращается исходный код прежде чем он будет выполнен. Если вам интересно взглянуть на то, как выглядит реальное абстрактное синтаксическое дерево - воспользуйтесь сайтом AST Explorer. Для того, чтобы сгенерировать AST для некоего фрагмента JS-кода, его достаточно поместить в соответствующее поле на странице.
- Оптимизация парсинга и JS-движки
JS-движки делают много полезного для того, чтобы избежать ненужной работы и оптимизировать процессы обработки кода. Вот несколько примеров.
Движок V8 поддерживает потоковую передачу скриптов и кэширование кода. Под потоковой передачей в данном случае понимается то, что система занимается парсингом скриптов, загружающихся асинхронно, и скриптов, выполнение которых отложено, в отдельном потоке, начиная это делать с момента начала загрузки кода. Это ведёт к тому, что парсинг завершается практически одновременно с завершением загрузки скрипта, что даёт примерно 10% уменьшение времени, необходимого на подготовку страниц к работе.
JavaScript-код обычно компилируется в байт-код при каждом посещении страницы. Этот байт-код, однако, теряется после того, как пользователь переходит на другую страницу. Происходит это из-за того, что скомпилированный код сильно зависит от состояния и контекста системы во время компиляции. Для того чтобы улучшить ситуацию в Chrome 42 появилась поддержка кэширования байт-кода. Благодаря этому новшеству скомпилированный код хранится локально, в результате, когда пользователь возвращается на уже посещённую страницу, для подготовки её к работе не нужно выполнять загрузку, парсинг и компиляцию скриптов. Это позволяет Chrome сэкономить примерно 40% времени на задачах парсинга и компиляции. Кроме того, в случае с мобильными устройствами, это ведёт к экономии заряда их аккумуляторов.
Движок Carakan, который применялся в браузере Opera и уже довольно давно заменён на V8, мог повторно использовать результаты компиляции уже обработанных скриптов. При этом не требовалось, чтобы эти скрипты были бы подключены к одной и той же странице или даже были бы загружены с одного домена. Эта техника кэширования, на самом деле, весьма эффективна и позволяет полностью отказаться от шага компиляции. Она полагается на типичные сценарии поведения пользователей, на то, как люди работают с веб-ресурсами. А именно, когда пользователь следует определённой последовательности действий, работая с веб-приложением, загружается один и тот же код.
Интерпретатор SpiderMonkey, используемый в FireFox, не занимается кэшированием всего подряд. Он поддерживает систему мониторинга, которая подсчитывает количество вызовов определённого скрипта. На основе этих показателей определяются участки кода, которые нуждаются в оптимизации, то есть - те, на которые приходится максимальная нагрузка.
Конечно, некоторые разработчики браузеров могут решить, что кэширование их продуктам и вовсе не нужно. Так, Масей Стачовяк, ведущий разработчик браузера Safari, говорит, что Safari не занимается кэшированием скомпилированного байт-кода. Возможность кэширования рассматривалась, но она до сих пор не реализована, так как генерация кода занимает менее 2% общего времени выполнения программ.
Эти оптимизации не влияют напрямую на парсинг исходного кода на JS. В ходе их применения делается всё возможное, чтобы, в определённых случаях, полностью пропустить этот шаг. Каким бы быстрым ни был парсинг, он, всё же, занимает некоторое время, а полное отсутствие парсинга - это, пожалуй, пример идеальной оптимизации.
- Сокращение времени подготовки веб-приложений к работе
Как мы выяснили выше, хорошо было бы свести необходимость в парсинге скриптов к минимуму, но совсем избавиться от него нельзя, поэтому поговорим о том, как сократить время, необходимое для подготовки веб-приложений к работе. На самом деле, для этого можно сделать очень много всего. Например, можно минимизировать объём JS-кода, входящего в приложение. Код маленького объёма, готовящий страницу к работе, можно быстрее разобрать, да и его выполнение, вероятнее всего, займёт меньше времени, чем у кода более объёмного.
Для того чтобы сократить объём кода, можно организовать загрузку на страницу только того, что ей действительно необходимо, а не некоего огромного куска кода, в который входит абсолютно всё, нужное для веб-проекта в целом. Так, например, паттерн PRPL (Push or Preload, Render, Pre-cache, Lazy load) продвигает именно такой подход к загрузке кода. В качестве альтернативного варианта можно проверить зависимости и посмотреть, есть ли в них что-то избыточное, такое, что приводит лишь к неоправданному разрастанию кодовой базы. На самом деле, тут мы затронули большую тему, достойную отдельного материала. Вернёмся к парсингу.
Итак, цель данного материала заключается в обсуждении методик, позволяющих веб-разработчику помочь парсеру быстрее делать его работу. Такие методики существуют. Современные JS-парсеры используют эвристические алгоритмы для того, чтобы определить, понадобится ли выполнить некий фрагмент кода как можно скорее, или его нужно будет выполнить позже. Основываясь на этих предсказаниях, парсер либо полностью анализирует фрагмент кода, применяя алгоритм жадного синтаксического анализа (eager parsing), либо использует ленивый алгоритм синтаксического анализа (lazy parsing). При полном анализе разбираются функции, которые нужно скомпилировать как можно скорее. В ходе этого процесса выполняется решение трёх основных задач: построение AST, создание иерархии областей видимости и поиск синтаксических ошибок. Ленивый анализ, с другой стороны, используется только для функций, которые пока не нуждаются в компиляции. Здесь не создаётся AST и не выполняется поиск ошибок. При таком подходе лишь создаётся иерархия областей видимости, что позволяет сэкономить примерно половину времени в сравнении с обработкой функций, которые нужно выполнить как можно скорее.
На самом деле, концепция это не новая. Даже устаревшие браузеры вроде IE9 поддерживают подобные подходы к оптимизации, хотя, конечно, современные системы ушли далеко вперёд.
Разберём пример, иллюстрирующий работу этих механизмов. Предположим, у нас имеется следующий JS-код:
function foo() {
function bar(x) {
return x + 10;
}
function baz(x, y) {
return x + y;
}
console.log(baz(100, 200));
}
Как и в предыдущем примере, код попадает в парсер, который выполняет его синтаксический анализ и формирует AST. В результате парсер представляет код, состоящий из следующих основных частей (на функцию foo обращать внимания не будем):
- Объявление функции bar, которая принимает один аргумент (x). Эта функция имеет одну команду возврата, она возвращает результат сложения x и 10.
- Объявление функции baz, которая принимает два аргумента (x и y). У неё тоже одна команда возврата, возвращает она результат сложения x и y.
- Выполнение вызова функции baz с двумя аргументами - 100 и 200.
- Выполнение вызова функции console.log с одним аргументом, которым является значение, возвращённое ранее вызванной функцией.
Вот как это выглядит.
Результат разбора кода примера без применения оптимизации
Поговорим о том, что здесь происходит. Парсер видит объявление функции bar, объявление функции baz, вызов функции baz и вызов функции console.log. Очевидно, разбирая этот фрагмент кода, парсер столкнётся с задачей, выполнение которой никак не отразится на результатах выполнения данной программы. Речь идёт об анализе функции bar. Почему анализ этой функции не несёт практической пользы? Всё дело в том, что функция bar, как минимум, в представленном фрагменте кода, никогда не вызывается. Этот простой пример может показаться надуманным, но во множестве реальных приложений имеется большое количество функций, которые никогда не вызываются.
В подобной ситуации, вместо того, чтобы заниматься разбором функции bar, мы можем просто сделать запись о том, что она объявлена, но нигде не используется. При этом настоящий парсинг этой функции производится тогда, когда в ней возникнет необходимость, непосредственно перед её выполнением. Естественно, при выполнении ленивого синтаксического анализа нужно обнаружить тело функции и сделать запись о её объявлении, но на этом работа заканчивается. Для такой функции не надо формировать абстрактное синтаксическое дерево, так как у системы нет сведений о том, что эту функцию планируется выполнять. Кроме того, не выделяется память из кучи, что обычно требует немалых системных ресурсов. Если в двух словах, то отказ от разбора ненужных функций ведёт к значительному повышению производительности кода.
В результате, в предыдущем примере, настоящий парсер сформирует структуру, напоминающую следующую схему.
Результат разбора кода примера с оптимизацией
Обратите внимание на то, что парсер сделал запись об объявлении функции bar, но дальнейшим её разбором не занимался. Система не предприняла никаких усилий для анализа кода функции. В данном случае тело функции представляло собой команду возврата результата простых вычислений. Однако в большинстве реальных приложений код функций может быть гораздо более длинным и сложным, содержащим множество команд возврата, условия, циклы, команды объявления переменных и вложенных функций. Разбор всего этого, при условии, что такие функции никогда не вызываются, представляет собой пустую трату времени.
В вышеописанной концепции нет ничего сложного, но её практическая реализация - задача не из лёгких. Здесь мы рассмотрели очень простой пример, а, на самом деле, при принятии решения о том, будет ли некий фрагмент кода востребован в программе, нужно анализировать и функции, и циклы, и условные операторы, и объекты. В целом можно сказать, что парсеру нужно обработать и проанализировать абсолютно всё, что есть в программе.
- Советы по оптимизации
Вот несколько рекомендаций, которыми вы можете воспользоваться для оптимизации веб-приложений:
- Проверьте зависимости проекта. Избавьтесь от всего ненужного.
- Разделите код на небольшие фрагменты вместо того, чтобы складывать его в один большой файл.
- Откладывайте, в тех ситуациях, когда это возможно, загрузку JS-скриптов. При обработке текущего маршрута пользователю можно выдавать только тот код, который необходим для нормальной работы, и ничего лишнего.
- Используйте инструменты разработчика и средства вроде DeviceTiming для того, чтобы находить узкие места своих проектов.
- Используйте средства вроде Optimize.js для того, чтобы помочь парсерам определиться с тем, какие фрагменты кода им нужно обработать как можно скорее.
Системы хранения данных
При проектировании веб-приложения чрезвычайно важно выбрать подходящие средства для локального хранения данных. Речь идёт о механизме, который позволит надёжно хранить информацию, будет способствовать снижению объёма данных, передаваемых между серверной и клиентской частями приложения, и при этом не ухудшит скорость реакции приложения на воздействия пользователя. Хорошо продуманная стратегия локального кэширования данных является центральным звеном в разработке мобильных веб-приложений, которые могут работать без подключения к интернету. Современные пользователи всё чаще и чаще относятся к подобным возможностям как к чему-то привычному и ожидаемому.
- Сравнение систем хранения данных
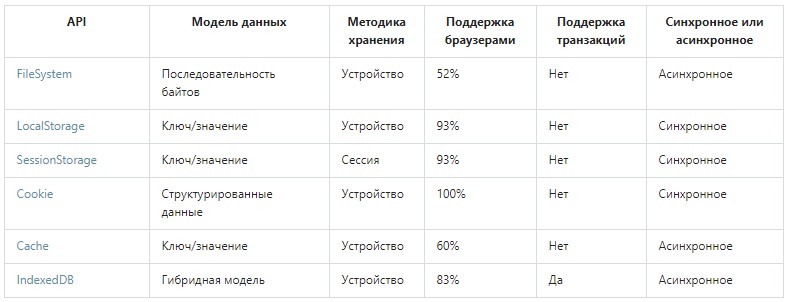
- API FileSystem
Благодаря использованию API FileSystem веб-приложения могут работать с выделенной областью локальной файловой системы пользователя. Приложение может просматривать содержимое хранилища, создавать файлы, выполнять операции чтения и записи.
Этот API состоит из следующих основных частей:
- Механизмы для управления файлами и для чтения файлов: File/Blob, FileList, FileReader
- Механизмы для создания файлов и записи в них данных: Blob, FileWriter
- Механизмы для работы с директориями и с файловой системой: DirectoryReader, FileEntry/DirectoryEntry, LocalFileSystem
API FileSystem не является стандартным, поэтому его не следует использовать в продакшне, так как оно будет работать не у всех пользователей. Различные реализации этого API могут сильно различаться, кроме того, весьма вероятно то, что в будущем оно может измениться.
Интерфейс filesystem этого API используются для представления файловой системы. Доступ к соответствующим объектам можно получить через свойство filesystem. Некоторые браузеры предлагают дополнительные API для создания файловых систем и управления ими.
Этот интерфейс не даёт веб-странице доступ к файловой системе пользователя. Вместо этого он позволяет работать с чем-то вроде виртуального диска, который находится в "песочнице", создаваемой браузером. Если вашему приложению нужен доступ к файловой системе пользователя, вам понадобится использовать другие механизмы.
Среди вариантов использования API FileSystem можно отметить следующие:
- Системы выгрузки данных. Когда пользователь выбирает файл или папку, которые нужно выгрузить на какой-нибудь сервер, эти данные копируются в локальное изолированное хранилище, после чего, по частям, отправляются на сервер.
- Приложения, оперирующие большими объёмами мультимедийных данных - игры, музыкальные проигрыватели.
- Приложения для редактирования звука и изображений, работающие без подключения к интернету или использующие локальный кэш большого объёма для ускорения работы. Данные, с которыми работают такие приложения, представляют собой последовательности байтов, которые могут иметь довольно большой объём. Хранилище для таких данных должно поддерживать возможность их записи и чтения.
- Оффлайновые видеопроигрыватели. Таким программам надо загружать большие файлы, которые можно просматривать без подключения к интернету. Это может понадобиться и при потоковой передаче данных, и для организации удобной системы перемещения по файлу.
- Оффлайновые почтовые клиенты. Такие программы могут загружать файлы, вложенные в электронные письма, и сохранять их локально.
- API LocalStorage
API LocalStorage, или локальное хранилище, позволяет работать с объектом Storage объекта Document с учётом принципа одинакового источника. Данные не теряются между сессиями. API LocalStorage похоже на API SessionStorage, сессионное хранилище, разница заключается в том, что данные в сессионном хранилище удаляются после того, как сессия страницы завершится, а данные в локальном хранилище хранятся постоянно.
Обратите внимание на то, что данные, размещённые в локальном или в сессионном хранилище привязаны к источнику страницы, который определяется комбинацией протокола, хоста и порта.
- API SessionStorage
API SessionStorage позволяет работать с объектом Storage сессии. API SessionStorage похоже на API LocalStorage, о котором мы говорили выше. Разница между ними, как уже было сказано, заключается во времени хранения данных, а именно, в случае с SessionStorage данные хранятся столько, сколько длится сессия. Длится она до тех пор, пока открыт браузер, при этом она сохраняется после перезагрузки страницы. Открытие страницы в новой вкладке или окне приведёт к инициированию новой сессии, это отличается от поведения сессионных куки-файлов. При этом, работая и с SessionStorage, и с LocalStorage, надо помнить о том, что данные в таких хранилищах привязаны к источнику страницы.
- API Cookie
Cookie (куки, веб-куки, браузерные куки) - это небольшие фрагменты информации, которые сервер отправляет браузеру. Браузер может их сохранять и отправлять серверу, используя их при формировании запросов к нему. Обычно они используются для идентификации конкретного экземпляра браузера, от которого поступают запросы. Например - для того, чтобы пользователь, после входа в систему, оставался бы в ней. Куки - это нечто вроде системы хранения информации о состоянии сеанса связи для протокола HTTP, который рассматривает каждый запрос, даже приходящий из одного и того же браузера, как совершенно независимый от других.
Куки используются для решения трёх основных задач:
- Управление сессией. На использовании куки основаны такие механизмы, как системы входа в веб-приложения, корзины покупателей в интернет-магазинах, хранение очков, набранных в браузерных играх. Речь идёт о хранении всего того, что нужно знать серверу во время работы с ним пользователя.
- Персонализация. Куки применяются для хранения данных о предпочтениях пользователя, о выбираемых им темах оформления сайта, и о прочих подобных вещах.
- Наблюдение за пользователем. С помощью куки выполняется запись и анализ поведения пользователя.
В своё время куки применялись как хранилище данных общего назначения. Хотя это и вполне нормальный способ использования куки, особенно, когда они были единственным способом хранения данных на клиенте, в наше время применять их в таком качестве не рекомендуется, отдав предпочтение более современным API. Куки отправляются с каждым запросом, поэтому они могут ухудшить производительность (особенно - на мобильных устройствах).
Существует два вида куки:
- Сессионные куки. Они удаляются после завершения сессии. Веб-браузеры могут использовать технику восстановления сессии, благодаря которой большинство сессионных куки хранятся постоянно, в результате сессии сохраняются даже после закрытия и повторного запуска браузера и открытия соответствующей страницы.
- Постоянные куки. Постоянные куки не теряют актуальности после завершения сессии. Они имеют определённый срок хранения, который определяется либо некоей датой (атрибут Expires), либо неким периодом времени (атрибут Max-Age).
Обратите внимание на то, что конфиденциальную или другую важную информацию не следует хранить в куки-файлах или передавать в HTTP-куки, так как весь механизм работы с куки, по своей сути, небезопасен.
- API Cache
Интерфейс Cache предоставляет механизм хранения данных для кэшируемых пар объектов Request / Response. Этот интерфейс определён в тех же спецификациях, что и сервис-воркеры, но доступен он не только воркерам. Интерфейс Cache доступен и в области видимости объекта window, его необязательно использовать только с сервис-воркерами.
Некий источник может иметь несколько именованных объектов Cache. Разработчик несёт ответственность за реализацию того, как его скрипт (например - в сервис-воркере) поддерживает кэш в актуальном состоянии. Элементы, сохранённые в кэше, не обновляются до тех пор, пока не будет сделан явный запрос на их обновление, срок их хранения не истекает, их можно лишь удалить из кэша. Для того чтобы открыть именованный объект кэша, можно воспользоваться командой CacheStorage.open(), после чего можно, обращаясь к нему, вызывать команды управления кэшем.
Кроме того, разработчик ответственен за периодическую очистку кэша. У каждого браузера имеется жёстко заданное ограничение на размер кэша, который выделяется конкретному источнику. Узнать примерное значение квоты кэширования можно, воспользовавшись API StorageEstimate.
Браузер делает всё, что в его силах, для того, чтобы поддерживать определённый объём доступного пространства кэша, но он может удалить кэш для некоего источника. Обычно браузер либо удаляет весь кэш, либо совершенно его не касается. Пользуясь кэшами, не забывайте о том, чтобы различать их в соответствии с версиями ваших скриптов, например, включая версию скрипта в имя кэша. Делается это для того, чтобы обеспечить безопасную работу различных версий скриптов с кэшем.
Интерфейс CacheStorage представляет хранилище для объектов Cache. Вот задачи, за решение которых отвечает этот интерфейс:
- Предоставление списка всех именованных кэшей, с которыми может работать сервис-воркер, или другой тип воркера. Работать с кэшем можно и через объект window.
- Поддерживает установление соответствия между строковыми именами и соответствующими объектами типа Cache.
- API IndexedDB
API IndexedDB - это СУБД, которая позволяет хранить данные средствами браузера. Так как это позволяет создавать веб-приложения, обладающие возможностями работы со сложными наборами данных даже без подключения к интернету, такие приложения могут одинаково хорошо себя чувствовать и при наличии соединения с сервером, и без него. IndexedDB находит применение в приложениях, которым нужно хранить большие объёмы данных (например, такое приложение может быть чем-то вроде каталога фильмов некоей службы, выдающей их напрокат), и которым необязательно поддерживать постоянное соединение с сетью для нормальной работы (например - это почтовые клиенты, менеджеры задач, записные книжки, и так далее).